Today we are going to see how we can scrape Cryptocurrency data using Python and BeautifulSoup is a simple and elegant manner.
This article aims to get you started on a real-world problem solving this article aims, so you get familiar and get practical results as fast as possible.
So the first thing we need is to make sure we have Python 3 installed. If not, you can just get Python 3 and get it installed before you proceed.
Then you can install beautiful soup.
pip3 install beautifulsoup4
We will also need the library's requests, lxml, and soup sieve to fetch data, break it down to XML, and to use CSS selectors. Install them using.
pip3 install requests soupsieve lxmlOnce installed, open an editor and type in.
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requestsNow let's go to the Yahoo cryptocurrency page and inspect the data we can get.
This is how it looks.
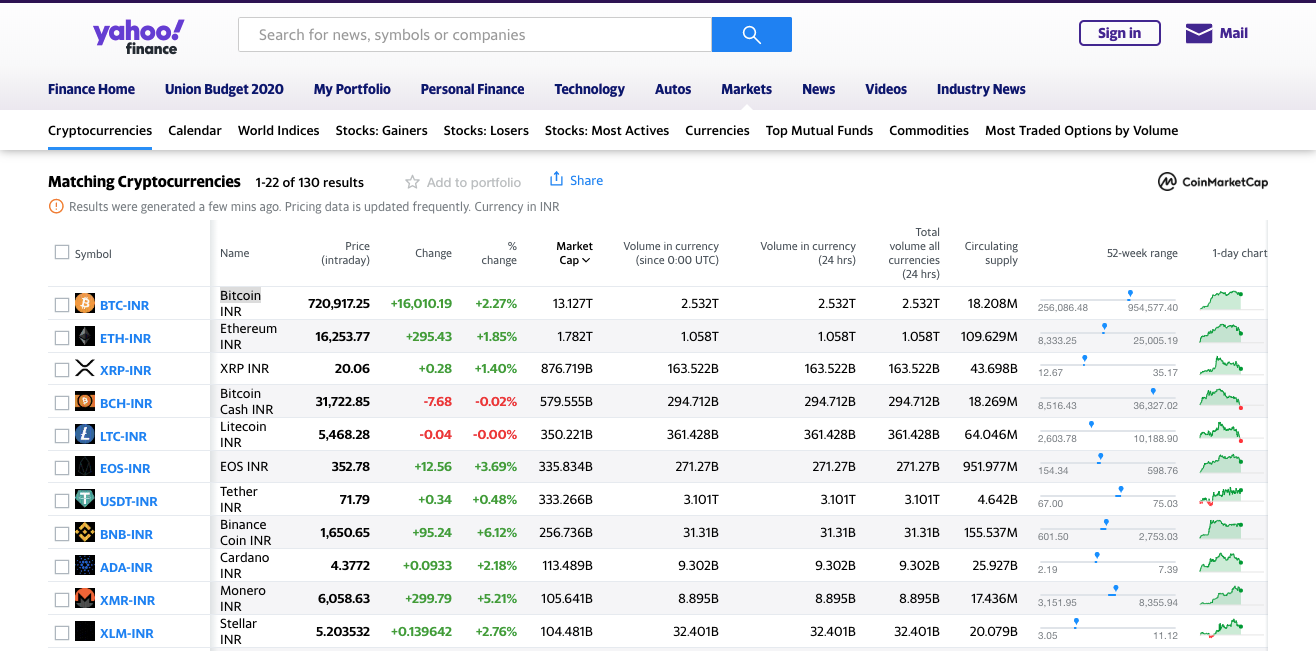
Back to our code now. Let's try and get this data by pretending we are a browser like this.
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url='https://in.finance.yahoo.com/cryptocurrencies'
response=requests.get(url,headers=headers)
print(response)Save this as yahoo_crypto_bs.py.
If you run it.
python3 yahoo_crypto_bs.pyYou will see the whole HTML page.
Now let's use CSS selectors to get to the data we want. To do that, let's go back to Chrome and open the inspect tool.
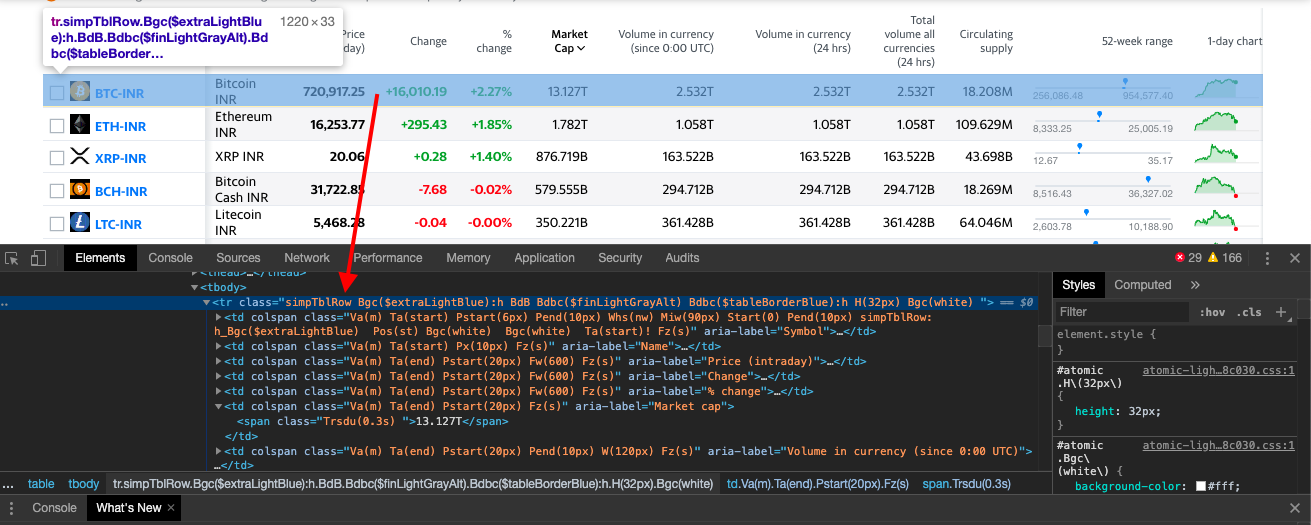
We notice that all the individual rows of data are contained in a with the class 'simpTblRow'. We can get BeautifulSoup to select that data like this.
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url='https://in.finance.yahoo.com/cryptocurrencies'
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.content,'lxml')
for item in soup.select('.simpTblRow'):
try:
print(item)
print('------------------')
except Exception as e:
raise e
print('')This prints all the content in each of the rows.
We can now pick out classes inside these rows that contain the data we want. The symbol is in the element with the attribute aria-label with the value Symbol.
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
url='https://in.finance.yahoo.com/cryptocurrencies'
header = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'
}
response=requests.get(url,headers=header)
soup=BeautifulSoup(response.content, 'lxml')
for item in soup.select('.simpTblRow'):
print(item.select('[aria-label=Symbol]')[0].get_text())
print('____________________________')If you run it, it will print out all the symbols.
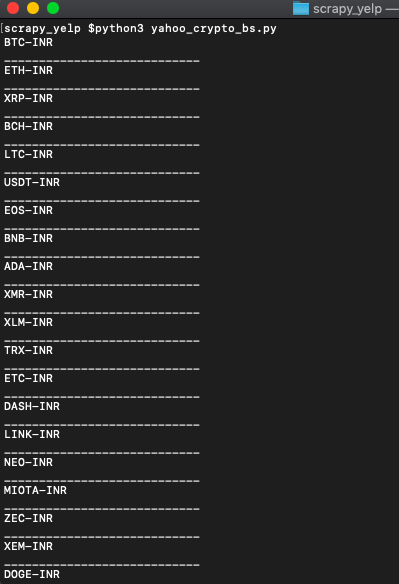
Bingo!! We got the symbols.
Now with the same process, we get the other data like Name, price, change, change percentage, etc.
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
url='https://in.finance.yahoo.com/cryptocurrencies'
header = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'
}
response=requests.get(url,headers=header)
soup=BeautifulSoup(response.content, 'lxml')
for item in soup.select('.simpTblRow'):
print(item.select('[aria-label=Symbol]')[0].get_text())
print(item.select('[aria-label=Name]')[0].get_text())
print(item.select('[aria-label*=Price]')[0].get_text())
print(item.select('[aria-label=Change]')[0].get_text())
print(item.select('[aria-label="% change"]')[0].get_text())
print(item.select('[aria-label="Market cap"]')[0].get_text())
print(item.select('[aria-label*="Volume in currency (since"]')[0].get_text())
print(item.select('[aria-label*="Volume in currency (24 hrs)"]')[0].get_text())
print(item.select('[aria-label*="Total volume all currencies (24 hrs)"]')[0].get_text())
print(item.select('[aria-label*="Circulating supply"]')[0].get_text())
print(item.select('[aria-label*="52-week range"]')[0].get_text())
print('____________________________')When we run it, it will print out every detail we want like this.
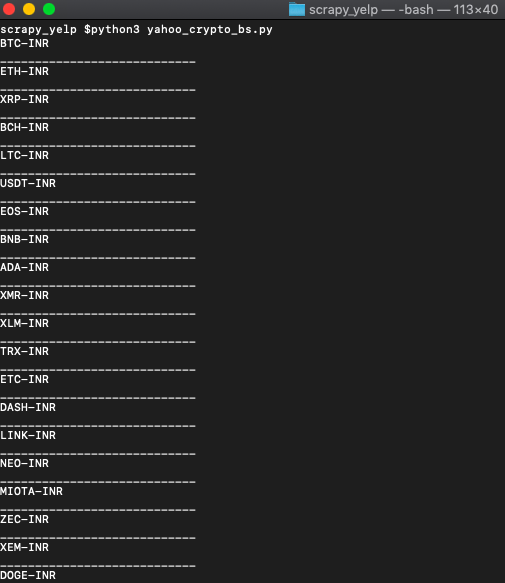
We even added a separator to show where each symbol data ends. You can now pass this data into an array or save it to CS and do whatever you want.
If you want to use this in production and want to scale to thousands of links, then you will find that you will get IP blocked quickly by Yahoo. In this scenario, using a rotating proxy service to rotate IPs is almost a must.
Otherwise, you tend to get IP blocked a lot by automatic location, usage, and bot detection algorithms.
Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly.
- With millions of high speed rotating proxies located all over the world
- With our automatic IP rotation
- With our automatic User-Agent-String rotation (which simulates requests from different, valid web browsers and web browser versions)
- With our automatic CAPTCHA solving technology
Hundreds of our customers have successfully solved the headache of IP blocks with a simple API.
A simple API can access the whole thing like below in any programming language.
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com"We have a running offer of 1000 API calls completely free. Register and get your free API Key here.