One of the most significant applications of Web Scraping in retail and e-commerce is in monitoring competitor product intelligence. This, when done well, can mean extra revenue and also will allow the retailer to ensure that they are always in the game and are not taken by surprise by anything the competition is doing.
Here is a simple script that does that. We will use BeautifulSoup to help us extract product and pricing information on Amazon.
To start with, this is the boilerplate code we need to get a page on Amazon and set up BeautifulSoup to help us use CSS selectors to query the page for meaningful data.
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url = 'https://www.amazon.com/Victrola-Bluetooth-Suitcase-Turntable-Turquoise/dp/B00UMVVUOC?pf_rd_p=f62b9627-0b3f-409a-81f2-c4d5e3c556d9&pd_rd_wg=oc1cu&pf_rd_r=FYVCAGRDA22E1G9T400R&ref_=pd_gw_unk&pd_rd_w=oaPrK&pd_rd_r=c678cac3-201d-4cc6-a88f-0a453f156cd5'
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.content,'lxml')
We are also p[assing the user agent headers to simulate a browser call, so we dont get blocked.
Now let's analyze the Amazon page for this Turntable.
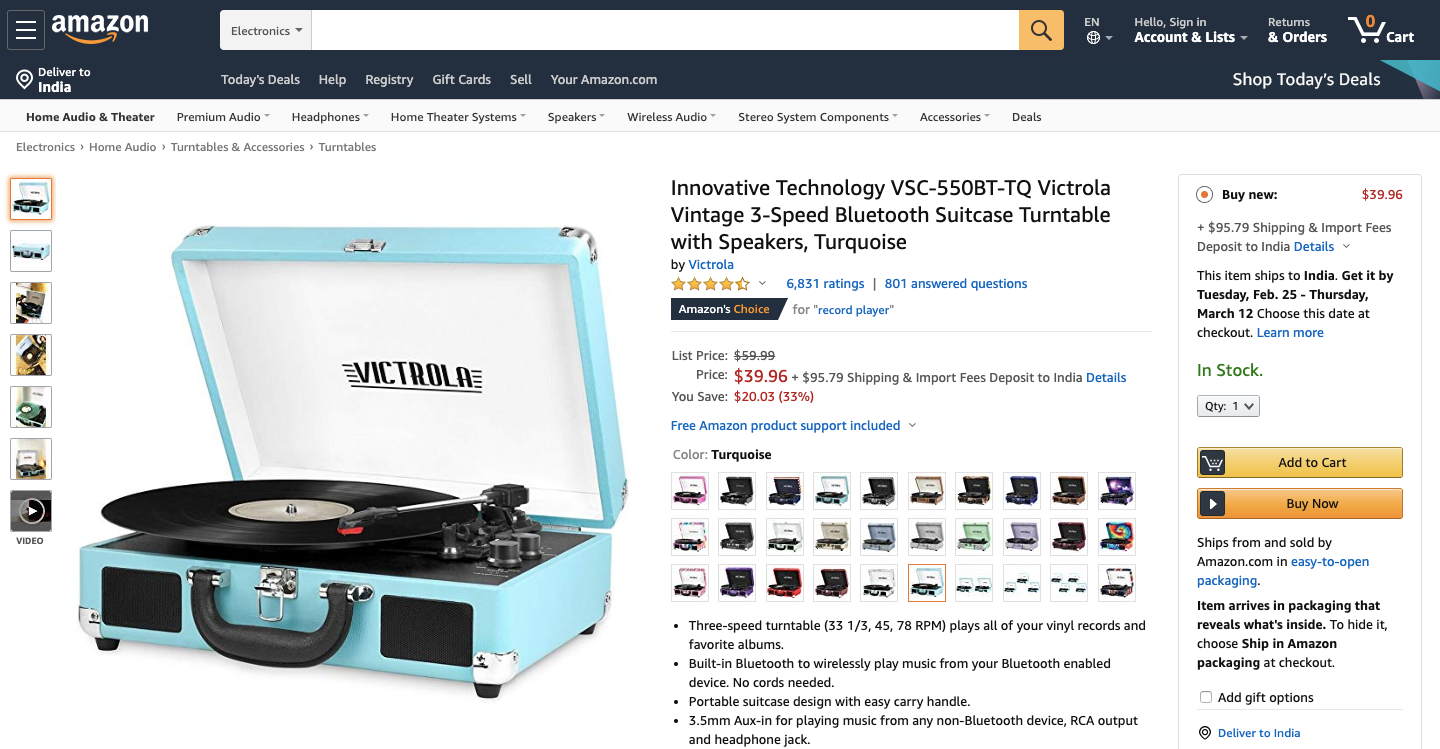
And when we inspect the page, we find that each of the items. HTML is encapsulated in a tag with the id product title.
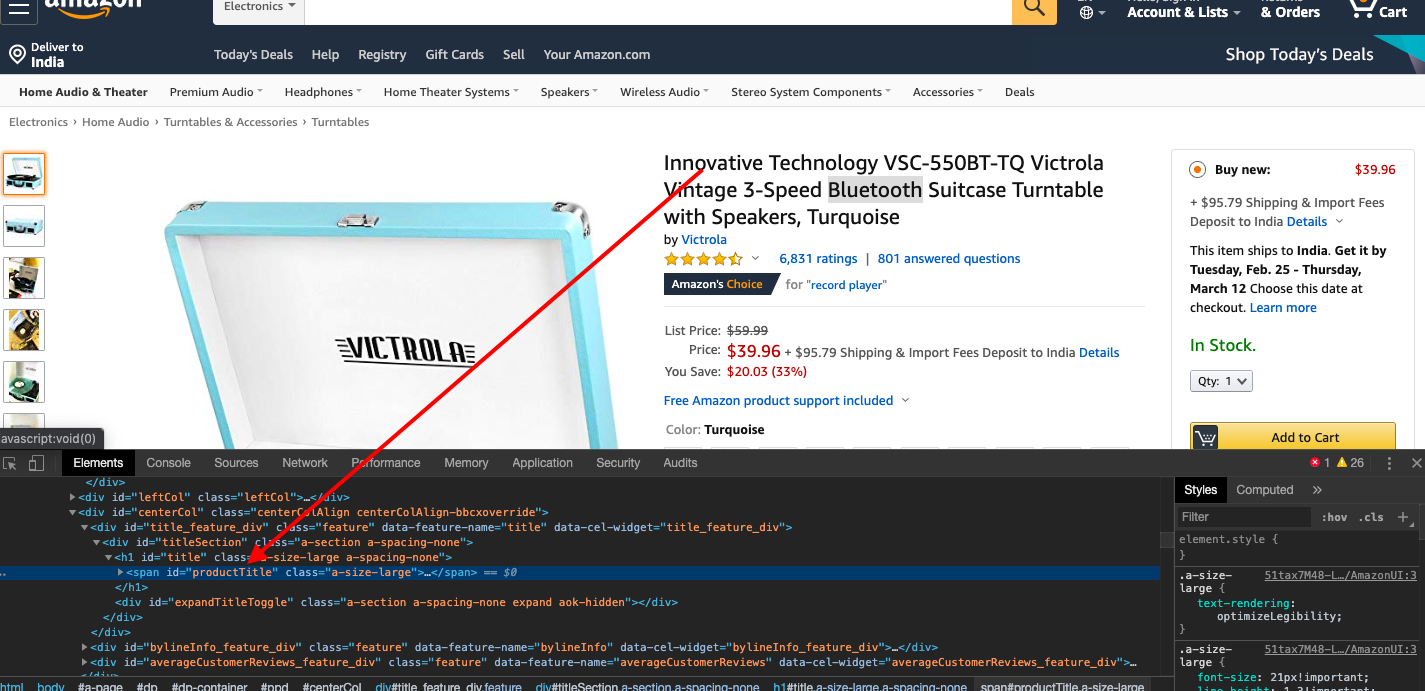
Things cannot get simpler for us.
This code should be able to retrieve the Title.
print('Title: ' soup.select('#productTitle')[0].get_text().strip())Putting the whole thing together, the code will look like this.
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url = 'https://www.amazon.com/Victrola-Bluetooth-Suitcase-Turntable-Turquoise/dp/B00UMVVUOC?pf_rd_p=f62b9627-0b3f-409a-81f2-c4d5e3c556d9&pd_rd_wg=oc1cu&pf_rd_r=FYVCAGRDA22E1G9T400R&ref_=pd_gw_unk&pd_rd_w=oaPrK&pd_rd_r=c678cac3-201d-4cc6-a88f-0a453f156cd5'
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.content,'lxml')
#print(soup.select('.a-carousel-card')[0].get_text())
try:
print('Title: ' soup.select('#productTitle')[0].get_text().strip())
print('Original price: ' soup.select('.priceBlockStrikePriceString')[0].get_text().strip())
print('Discounted price: ' soup.select('#priceblock_ourprice')[0].get_text().strip())
print('Shipping: ' soup.select('#ourprice_shippingmessage .a-color-secondary')[0].get_text().strip())
print('Features follow:')
for item in soup.select('#feature-bullets li'):
print('\t' item.select('.a-list-item')[0].get_text().strip())
except Exception as e:
raise e
print('')You will see that for the features, we have created an addition for each loop. This is because we find that the features are bullet points inside a tag with the id feature-bullets. And when you run it.
python3 AmazonProcutInfo.pyYou get this data.
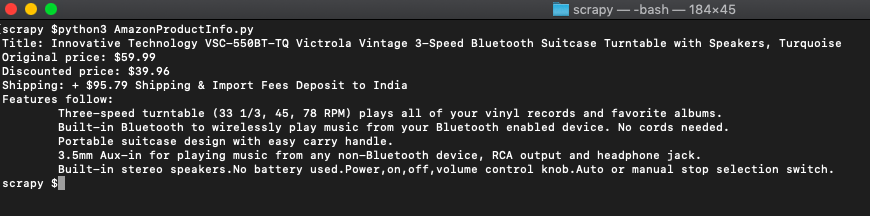
We get the Title, Original price, Discount price, Shipping info, and the feature breakdown.
You can now save this to a db and run this script every day or every hour and on different products as needed.
In more advanced implementations, you will need to even rotate the User-Agent string, so Amazon cant tell it the same browser!
If we get a little bit more advanced, you will realize that Amazon can simply block your IP, ignoring all your other tricks. This is a bummer, and this is where most web crawling projects fail.
Overcoming IP Blocks
Investing in a private rotating proxy service like Proxies API can most of the time make the difference between a successful and headache-free web scraping project, which gets the job done consistently and one that never really works.
Plus, with the 1000 free API calls running an offer, you have almost nothing to lose by using our rotating proxy and comparing notes. It only takes one line of integration to its hardly disruptive.
Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly.
- With millions of high speed rotating proxies located all over the world
- With our automatic IP rotation
- With our automatic User-Agent-String rotation (which simulates requests from different, valid web browsers and web browser versions)
- With our automatic CAPTCHA solving technology
Hundreds of our customers have successfully solved the headache of IP blocks with a simple API.
A simple API can access the whole thing like below in any programming language.
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com"We have a running offer of 1000 API calls completely free. Register and get your free API Key here.