import SocketServer
import SimpleHTTPServer
import urllib
PORT = 9097
then we inherit the SimpleHTTPRequestHandler to create our own proxy. The do_GET is called for all get requests.
class MyProxy(SimpleHTTPServer.SimpleHTTPRequestHandler):
def do_GET(self):
url=self.path[1:]
self.send_response(200)
self.end_headers()
self.copyfile(urllib.urlopen(url), self.wfile)the url will have a slash (/) in the beginning from the browsers so we need to remove it using
url=self.path[1:]Browsers need the headers to report a successful fetch with the HTTP status code of 200 so we send those headers.
self.send_response(200)
self.end_headers()
self.copyfile(urllib.urlopen(url), self.wfile)The last line uses the urllib library to fetch the URL and write it back to the browser using the copy file function.
to run this we use the ForkingTCPServer mode and pass it to our class to handle the interrupts.
httpd = SocketServer.ForkingTCPServer(('', PORT), MyProxy)
httpd.serve_forever()We put the whole thing together in 17 lines.
import SocketServer
import SimpleHTTPServer
import urllib
PORT = 9097
class MyProxy(SimpleHTTPServer.SimpleHTTPRequestHandler):
def do_GET(self):
url=self.path[1:]
self.send_response(200)
self.end_headers()
self.copyfile(urllib.urlopen(url), self.wfile)
httpd = SocketServer.ForkingTCPServer(('', PORT), MyProxy)
print ("Now serving at" str(PORT))
httpd.serve_forever()Save the file as simpleServer.py and run.
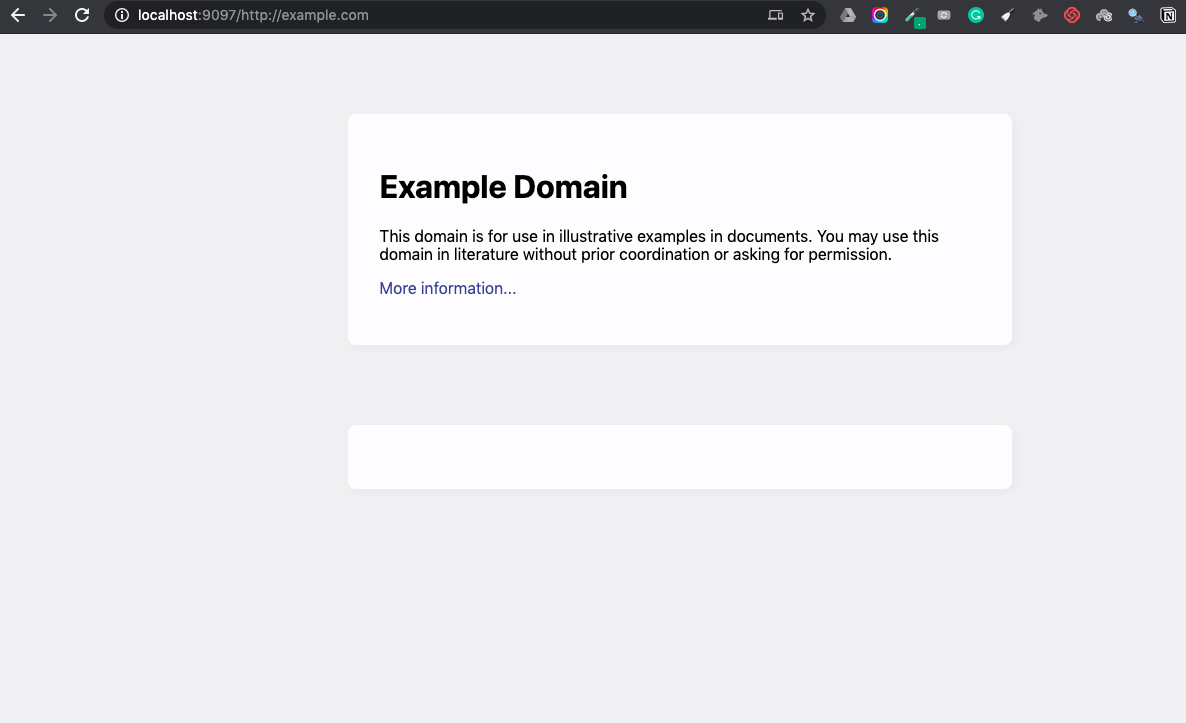
And call it from the browser like so.
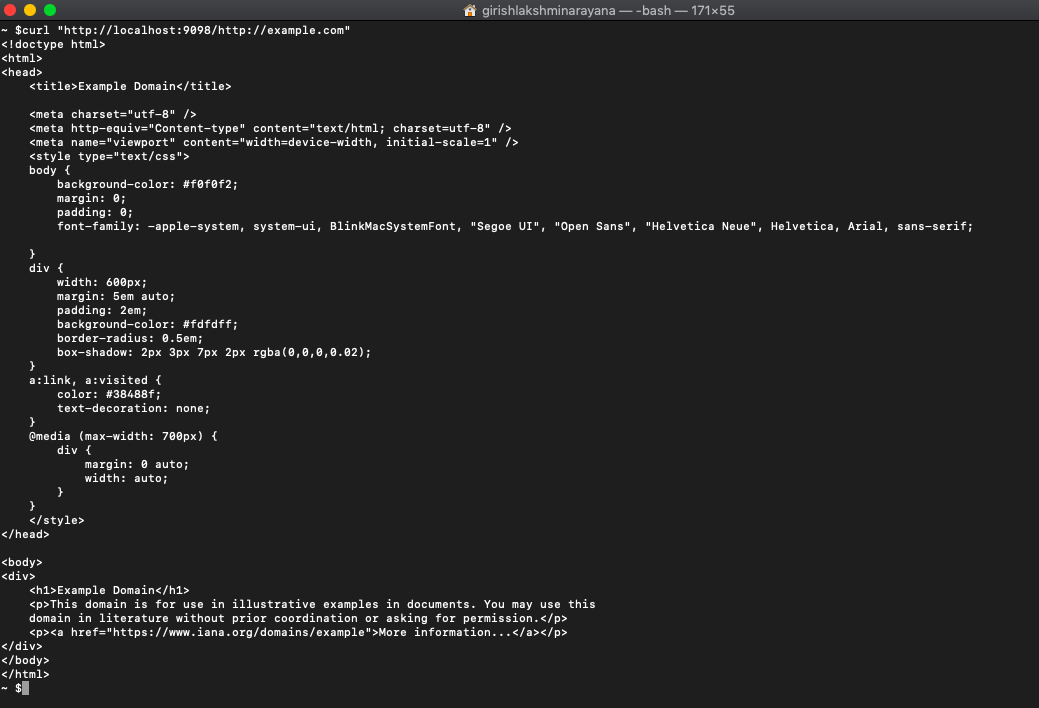
Or using cURL which is probably more appropriate as a programmer trying to scrape just HTML because we haven't built-in support for getting subsequent images, CSS, and JS files which the browser will call for.
curl "http://localhost:9098/http://example.com"
You get:
This is great as a learning exercise but it is easy to see that even the proxy server itself is prone to get blocked as it uses a single IP. In this scenario where you may want a proxy that handles thousands of fetches every day using a professional rotating proxy service to rotate IPs is almost a must.
Otherwise, you tend to get IP blocked a lot by automatic location, usage, and bot detection algorithms.
Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly.
With millions of high speed rotating proxies located all over the world,
With our automatic IP rotation
With our automatic User-Agent-String rotation (which simulates requests from different, valid web browsers and web browser versions)
With our automatic CAPTCHA solving technology,
Hundreds of our customers have successfully solved the headache of IP blocks with a simple API.
The whole thing can be accessed by a simple API like below in any programming language.
In fact, you don't even have to take the pain of loading Puppeteer as we render Javascript behind the scenes and you can just get the data and parse it any language like Node, Puppeteer or PHP or using any framework like Scrapy or Nutch. In all these cases you can just call the URL with render support like so.
curl "http://api.proxiesapi.com/?key=API_KEY&render=true&url=https://example.com"We have a running offer of 1000 API calls completely free. Register and get your free API Key here.