In an earlier post, we have seen how we can build a simple web scraper that scrapes Airbnb listings. In a perfect world, this is enough. But in the real world, you will see that scrapers fail more often than silicon valley startups.
This can be avoided by building in monitoring systems inside of our scraper. This is an example of a simple monitoring system that converts the code in the blog post above to something that is more monitor-able, debuggable, and reliable. You can make it more sophisticated by adding database logging and other hooks to it.
First, we need a working list of places a scraper/crawler could fail. Here is a simple starter list.
List of places scrapers fail
- Url fetch errors: Website is down
- Url fetch errors: Our internet is down
- Url fetch errors: Website times out
- Url fetch errors: too many redirects
- Url fetch errors: IP blocked
- Url fetch errors: Captcha challenge issued
- Scraping errors: Website changed the pattern
- Scraping errors: Some data pieces are missing
There are more. But we can address these in our example.
Here is how the simple Airbnb scraper looked when we first started.
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url = 'https://www.airbnb.co.in/s/New-York--NY--United-States/homes?query=New York, NY, United States&checkin=2020-03-12&checkout=2020-03-19&adults=4&children=1&infants=0&guests=5&place_id=ChIJOwg_06VPwokRYv534QaPC8g&refinement_paths[]=/for_you&toddlers=0&source=mc_search_bar&search_type=unknown'
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.content,'lxml')
for item in soup.select('[itemprop=itemListElement]'):
try:
print('----------------------------------------')
print(item.select('a')[0]['aria-label'])
print(item.select('a')[0]['href'])
print(item.select('._krjbj')[0].get_text())
print(item.select('._krjbj')[1].get_text())
print(item.select('._16shi2n')[0].get_text())
print(item.select('._zkkcbwd')[0].get_text())
print(name)
print('----------------------------------------')
except Exception as e:
#raise e
print('')We will now define a simple function that handles all the monitoring needs like so.
errorCount=0
def monitor(eventType, email):
#This code saves the errors to a file log and also sends an email alerting the developers of a failure point
# You can write code that logs this to a server as well
global errorCount
errorCount=errorCount 1
now = datetime.now()
dt_string = now.strftime("%d/%m/%Y %H:%M:%S")
#Save to log
with open("monitor.txt", "a") as myfile:
myfile.write("[" dt_string "] " "Scraper Error: " eventType "\r\n")
return
#Now send an email
s = smtplib.SMTP('smtp.gmail.com', 587)
s.starttls()
s.login("mohan@proxiesapi.com", "mypassword")
message = "Scraper Error: " eventType
s.sendmail("mohan@proxiesapi.com", email, message)
s.quit()
#too many errors. Something very wrong. Abort script
if (errorCount>3):
with open("monitor.txt", "a") as myfile:
myfile.write("[" dt_string "] " "Full abort after " errorCount " errors\r\n")
sys.exit()That's a lot of code. Let's delve into it.
- The code tries to maintain a count of code. This is an overall trigger to abort if the total number of errors in a script goes beyond an acceptable limit.
- The inserts a timestamp and URL (you can extend to capture other payloads)
- It tries to append everything to a log file.
- It will also send an email to the developer so they can act on it immediately.
- You can add a database logging to it very easily.
Now, let's add this to several checkpoints in our code so that everything is captured. In this example, we only bother with the errors. You can, of course, change this to log successes as well.
try:
response=requests.get(url,headers=headers)
except requests.exceptions.Timeout:
monitor('Airbnb timed out', 'xxx@gmail.com')
except requests.exceptions.TooManyRedirects:
monitor('Too many redirects Airbnb', 'xxx@gmail.com')
except requests.exceptions.RequestException as e:
monitor('Catastrophic error requesting Airbnb', 'xxx@gmail.com')
print(e)
sys.exit(1)Just the requests object can fail in many ways. The code above takes care of that. You can extend this to other error codes as well.
if (len(response.content)<200):
monitor('Airbnb returned unusual results', 'xxx@gmail.com')This code checks if there is an IP block or a Captcha challenge because we KNOW that the length of the HTML is more than 200 bytes usually.
if (len(soup.select('[itemprop=itemListElement]'))<1):
monitor('Airbnb pattern changed. Cant fetch anything', 'xxx@gmail.com')This code checks if the primary pattern is still working. In the above example, its a deal-breaker. It issues an alert.
You can apply this to individual data pieces in your selector codes as well.
Here is the full code.
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
import smtplib
from datetime import datetime
import sys
errorCount=0
def monitor(eventType, email):
#This code saves the errors to a file log and also sends an email alerting the developers of a failure point
# You can write code that logs this to a server as well
global errorCount
errorCount=errorCount 1
now = datetime.now()
dt_string = now.strftime("%d/%m/%Y %H:%M:%S")
#Save to log
with open("monitor.txt", "a") as myfile:
myfile.write("[" dt_string "] " "Scraper Error: " eventType "\r\n")
return
#Now send an email
s = smtplib.SMTP('smtp.gmail.com', 587)
s.starttls()
s.login("mohan@proxiesapi.com", "mypassword")
message = "Scraper Error: " eventType
s.sendmail("mohan@proxiesapi.com", email, message)
s.quit()
#too many errors. Something very wrong. Abort script
if (errorCount>3):
with open("monitor.txt", "a") as myfile:
myfile.write("[" dt_string "] " "Full abort after " errorCount " errors\r\n")
sys.exit()
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url = 'https://www.airbnb.co.in/s/New-York--NY--United-States/homes?query=New York, NY, United States&checkin=2020-03-12&checkout=2020-03-19&adults=4&children=1&infants=0&guests=5&place_id=ChIJOwg_06VPwokRYv534QaPC8g&refinement_paths[]=/for_you&toddlers=0&source=mc_search_bar&search_type=unknown'
try:
response=requests.get(url,headers=headers)
except requests.exceptions.Timeout:
monitor('Airbnb timed out', 'xxx@gmail.com')
except requests.exceptions.TooManyRedirects:
monitor('Too many redirects Airbnb', 'xxx@gmail.com')
except requests.exceptions.RequestException as e:
monitor('Catastrophic error requesting Airbnb', 'xxx@gmail.com')
print(e)
sys.exit(1)
monitor('Unable to reach Airbnb', 'xxx@gmail.com')
monitor('Airbnb pattern changed', 'xxx@gmail.com')
monitor('Airbnb timed out', 'xxx@gmail.com')
monitor('Catastrophic error requesting Airbnb', 'xxx@gmail.com')
if (len(response.content)<200):
monitor('Airbnb returned unusual results', 'xxx@gmail.com')
soup=BeautifulSoup(response.content,'lxml')
if (len(soup.select('[itemprop=itemListElement]'))<1):
monitor('Airbnb pattern changed. Cant fetch anything', 'xxx@gmail.com')
for item in soup.select('[itemprop=itemListElement]'):
try:
print('----------------------------------------')
print(item.select('a')[0]['aria-label'])
print(item.select('a')[0]['href'])
print(item.select('._krjbj')[0].get_text())
print(item.select('._krjbj')[1].get_text())
print(item.select('._16shi2n')[0].get_text())
print(item.select('._zkkcbwd')[0].get_text())
print(name)
print('----------------------------------------')
except Exception as e:
#raise e
print('')When run, it could produce data like this in the log file.
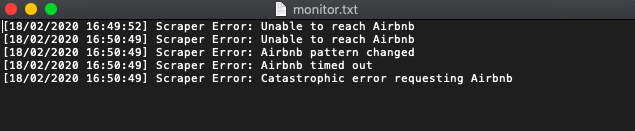
In more advanced implementations, you will need even to rotate the User-Agent string, so Airbnb cant tell its the same browser!
If we get a little bit more advanced, you will realize that Airbnb can simply block your IP, ignoring all your other tricks. This is a bummer, and this is where most web crawling projects fail.
Overcoming IP Blocks
Investing in a private rotating proxy service like Proxies API can most of the time make the difference between a successful and headache-free web scraping project, which gets the job done consistently and one that never really works.
Plus, with the 1000 free API calls running an offer, you have almost nothing to lose by using our rotating proxy and comparing notes. It only takes one line of integration to its hardly disruptive.
Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly.
- With millions of high speed rotating proxies located all over the world
- With our automatic IP rotation
- With our automatic User-Agent-String rotation (which simulates requests from different, valid web browsers and web browser versions)
- With our automatic CAPTCHA solving technology
Hundreds of our customers have successfully solved the headache of IP blocks with a simple API.
A simple API can access the whole thing like below in any programming language.
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com"We have a running offer of 1000 API calls completely free. Register and get your free API Key here.