Web scraping is a powerful technique for extracting data from websites. In this guide, we will walk you through the process of scraping Yelp business listings step by step. Yelp is a popular platform for finding information about local businesses, and by the end of this tutorial, you'll have a good understanding of how to scrape data from it.
This is the page we are talking about
Prerequisites
Before we start, let's make sure you have all the necessary tools in place. We'll be using the Elixir programming language for this project, so you'll need a few Elixir libraries:
You can install these libraries using Elixir's package manager, mix, with the following commands:
mix escript.install hex httpoison
mix escript.install hex floki
Premium Proxies and Anti-Bot Measures
Before diving into the code, it's essential to understand that Yelp employs anti-bot measures to prevent web scraping. To bypass these measures, you should consider using premium proxies. Premium proxies offer several advantages:
You can obtain premium proxies from services like ProxiesAPI. Be sure to have your authentication key ready, as you'll need it in the code.
Understanding the Code
Now, let's take a closer look at the code that scrapes Yelp business listings. The code provided here is functional and should not be modified. We will guide you through each section, explaining its purpose and functionality.
# Required modules
alias HTTPoison.Client, as: HttpClient
import :crypto
# URL of the Yelp search page
url = "<https://www.yelp.com/search?find_desc=chinese&find_loc=San+Francisco%2C+CA>"
In this section, we start by importing the necessary modules,
# URL-encode the URL
encoded_url = :inet.url_encode(url, reserved: true)
Here, we URL-encode the Yelp URL using the
# API URL with the encoded Yelp URL
api_url = "<http://api.proxiesapi.com/?premium=true&auth_key=YOUR_AUTH_KEY&url=#{encoded_url}>"
This part constructs the API URL for ProxiesAPI, incorporating your authentication key and the encoded Yelp URL.
# Define user-agent header to simulate a browser request
headers = [
{"User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"},
{"Accept-Language", "en-US,en;q=0.5"},
{"Accept-Encoding", "gzip, deflate, br"},
{"Referer", "<https://www.google.com/>"}
]
In this section, we define a set of headers to simulate a browser request. This step is crucial to prevent Yelp from detecting and blocking our scraping activities.
# Send an HTTP GET request to the URL with the headers
{:ok, response} = HttpClient.get(api_url, headers)
Here, we use the
# Write the HTML response to a file
File.write("yelp_html.html", response.body, [:binary])
This code writes the HTML response from the request to a file named "yelp_html.html" in binary format. We'll use this file for parsing and extracting data.
# Check if the request was successful (status code 200)
case response.status_code do
200 ->
# Parse the HTML content of the page using Floki (HTML parsing library)
{:ok, document} = Floki.parse_document(response.body)
In this section, we check if the HTTP request was successful by examining the status code. A status code of 200 indicates a successful request. If successful, we proceed to parse the HTML content using Floki, an HTML parsing library.
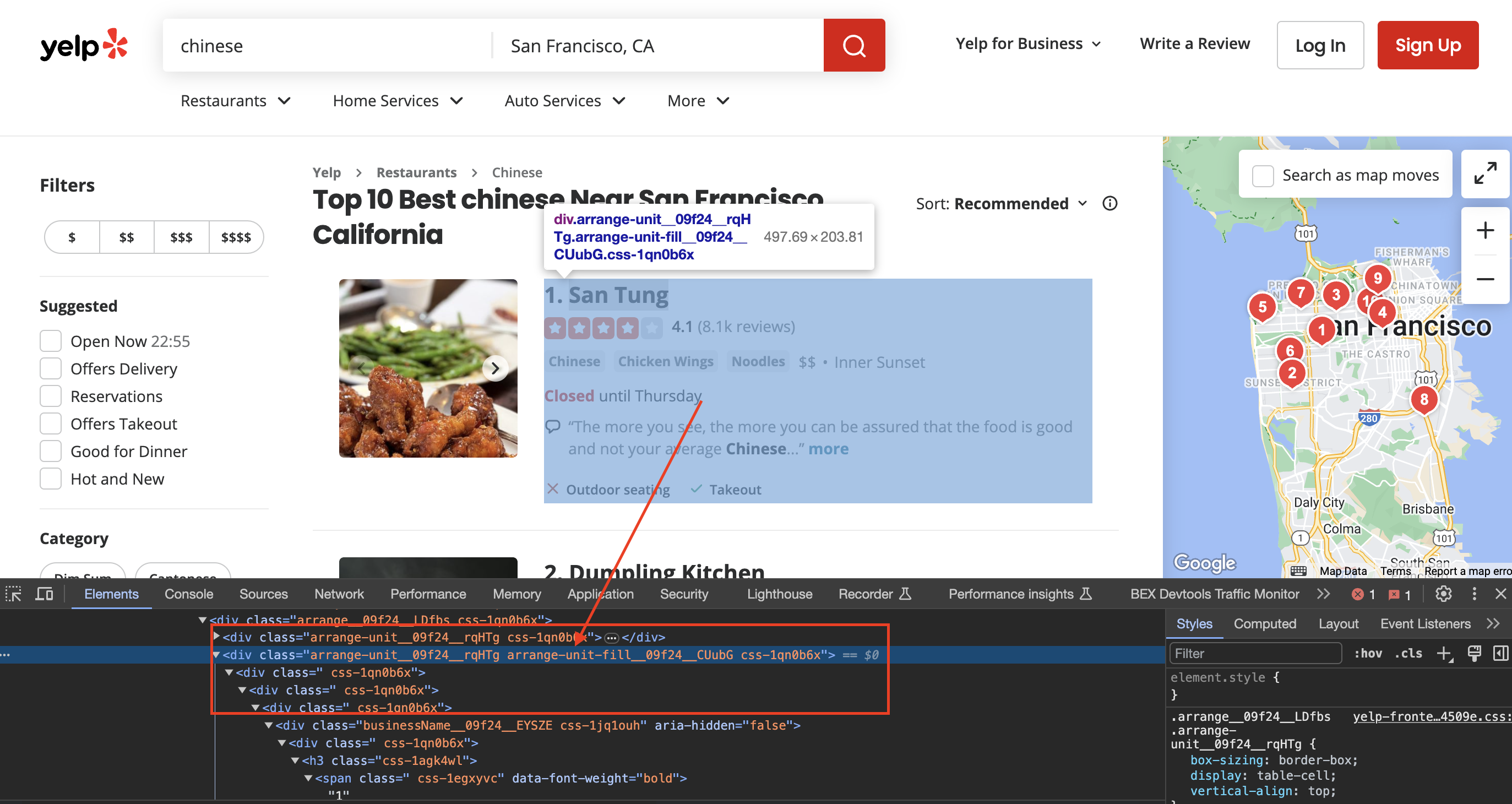
Inspecting the page
When we inspect the page we can see that the div has classes called arrange-unit__09f24__rqHTg arrange-unit-fill__09f24__CUubG css-1qn0b6x
# Find all the listings
listings = Floki.find(document, "div.arrange-unit__09f24__rqHTg.arrange-unit-fill__09f24__CUubG.css-1qn0b6x")
Now, we locate all the listings on the Yelp page using a specific selector. The selector
# Output the number of listings
IO.puts("Number of listings: #{length(listings)}")
# Loop through each listing and extract information
Enum.each(listings, fn listing ->
Here, we count the number of listings found and print it. Then, we start looping through each listing to extract relevant information.
# Extract business name
business_name_elem = Floki.find_one(listing, "a.css-19v1rkv")
business_name = Floki.text(business_name_elem) |> String.trim()
Inside the loop, we begin by extracting the business name using the selector
# Check if business name is not "N/A"
if business_name != "N/A" do
We perform a check to ensure that the business name is not "N/A" before proceeding with further data extraction.
# Extract rating
rating_elem = Floki.find_one(listing, "span.css-gutk1c")
rating = Floki.text(rating_elem) |> String.trim()
# Extract price range
price_range_elem = Floki.find_one(listing, "span.priceRange__09f24__mmOuH")
price_range = Floki.text(price_range_elem) |> String.trim()
# Extract number of reviews and location
span_elements = Floki.find(listing, "span.css-chan6m")
num_reviews = "N/A"
location = "N/A"
case length(span_elements) do
n when n >= 2 ->
num_reviews = span_elements |> hd() |> Floki.text() |> String.trim()
location = span_elements |> hd(1) |> Floki.text() |> String.trim()
1 ->
text = span_elements |> hd() |> Floki.text() |> String.trim()
if String.match?(text
, ~r/^\\d+$/) do
num_reviews = text
else
location = text
end
_ ->
:ok
end
Within this block, we extract the rating, price range, number of reviews, and location. We use specific selectors for each piece of information. The code also handles variations in the structure of the HTML.
# Print extracted information
IO.puts("Business Name: #{business_name}")
IO.puts("Rating: #{rating}")
IO.puts("Number of Reviews: #{num_reviews}")
IO.puts("Price Range: #{price_range}")
IO.puts("Location: #{location}")
IO.puts("=" <> String.duplicate("=", 30))
end
end)
_ ->
IO.puts("Failed to retrieve data. Status Code: #{response.status_code}")
end
Finally, we print the extracted information for each listing, including business name, rating, number of reviews, price range, and location. We also include formatting to make the output clear. If the HTTP request is unsuccessful (status code other than 200), we print an error message.
Full code:
# Required modules
alias HTTPoison.Client, as: HttpClient
import :crypto
# URL of the Yelp search page
url = "https://www.yelp.com/search?find_desc=chinese&find_loc=San+Francisco%2C+CA"
# URL-encode the URL
encoded_url = :inet.url_encode(url, reserved: true)
# API URL with the encoded Yelp URL
api_url = "http://api.proxiesapi.com/?premium=true&auth_key=YOUR_AUTH_KEY&url=#{encoded_url}"
# Define user-agent header to simulate a browser request
headers = [
{"User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"},
{"Accept-Language", "en-US,en;q=0.5"},
{"Accept-Encoding", "gzip, deflate, br"},
{"Referer", "https://www.google.com/"}
]
# Send an HTTP GET request to the URL with the headers
{:ok, response} = HttpClient.get(api_url, headers)
# Write the HTML response to a file
File.write("yelp_html.html", response.body, [:binary])
# Check if the request was successful (status code 200)
case response.status_code do
200 ->
# Parse the HTML content of the page using Floki (HTML parsing library)
{:ok, document} = Floki.parse_document(response.body)
# Find all the listings
listings = Floki.find(document, "div.arrange-unit__09f24__rqHTg.arrange-unit-fill__09f24__CUubG.css-1qn0b6x")
IO.puts("Number of listings: #{length(listings)}")
# Loop through each listing and extract information
Enum.each(listings, fn listing ->
# Assuming you've already extracted the information as shown in your code
# Check if business name exists
business_name_elem = Floki.find_one(listing, "a.css-19v1rkv")
business_name = Floki.text(business_name_elem) |> String.trim()
# If business name is not "N/A," then print the information
if business_name != "N/A" do
# Check if rating exists
rating_elem = Floki.find_one(listing, "span.css-gutk1c")
rating = Floki.text(rating_elem) |> String.trim()
# Check if price range exists
price_range_elem = Floki.find_one(listing, "span.priceRange__09f24__mmOuH")
price_range = Floki.text(price_range_elem) |> String.trim()
# Find all <span> elements inside the listing
span_elements = Floki.find(listing, "span.css-chan6m")
# Initialize num_reviews and location as "N/A"
num_reviews = "N/A"
location = "N/A"
# Check if there are at least two <span> elements
case length(span_elements) do
n when n >= 2 ->
# The first <span> element is for Number of Reviews
num_reviews = span_elements |> hd() |> Floki.text() |> String.trim()
# The second <span> element is for Location
location = span_elements |> hd(1) |> Floki.text() |> String.trim()
1 ->
# If there's only one <span> element, check if it's for Number of Reviews or Location
text = span_elements |> hd() |> Floki.text() |> String.trim()
if String.match?(text, ~r/^\d+$/) do
num_reviews = text
else
location = text
end
_ ->
:ok
end
# Print the extracted information
IO.puts("Business Name: #{business_name}")
IO.puts("Rating: #{rating}")
IO.puts("Number of Reviews: #{num_reviews}")
IO.puts("Price Range: #{price_range}")
IO.puts("Location: #{location}")
IO.puts("=" <> String.duplicate("=", 30))
end
end)
_ ->
IO.puts("Failed to retrieve data. Status Code: #{response.status_code}")
endConclusion and Next Steps
In this guide, we've covered the entire process of scraping Yelp business listings. You've learned how to make HTTP requests, parse HTML with Floki, and extract valuable information from web pages.
Next steps could include analyzing the scraped data, automating data collection on a regular basis, or expanding the scraping project to gather more information.
Happy scraping!