Have you ever wanted to extract data from Yelp listings for further analysis? For example, gathering information on pricing, ratings and reviews for competing businesses in your area? Web scraping provides a programmatic way to extract this data.
In this comprehensive, practical guide for beginners, we will walk through how to scrape Yelp business listings using Jsoup and Java.
This is the page we are talking about
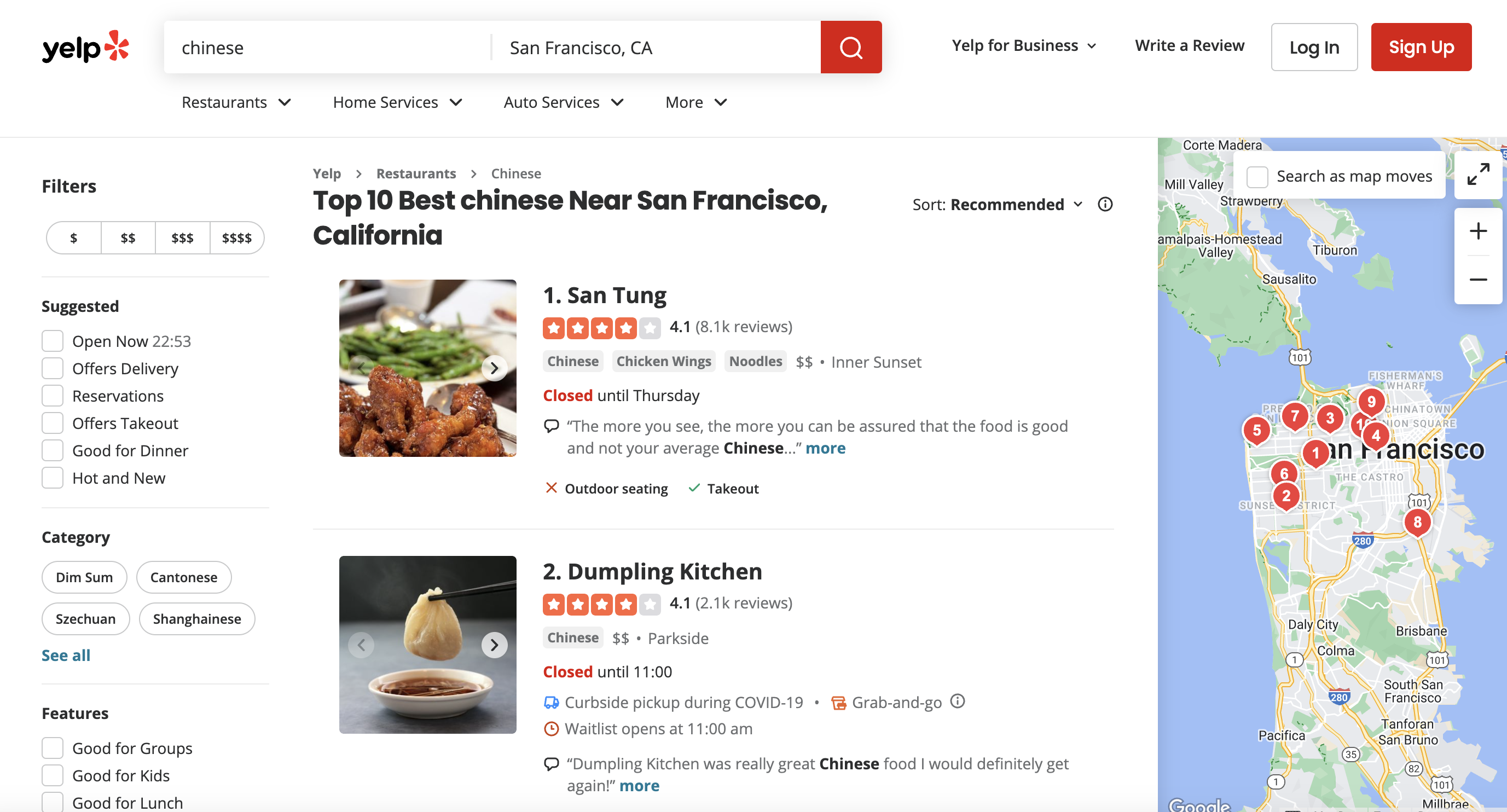
Why Proxies are Needed
Before jumping into the code, it's important to understand why proxies are used. Yelp employs strict anti-bot mechanisms to prevent large-scale automated scraping. Sending requests directly from your own IP address can get you blocked.
Premium proxies act as an intermediary, allowing requests to appear from residential IP addresses instead of your own. This mimics real user behavior, bypassing blocks.
The code we will go through uses the ProxiesAPI service to route requests, enabling stable extraction of data from Yelp.
Installing Jsoup
Jsoup is a Java library used for web scraping and parsing HTML documents. To follow along, you will need to install Jsoup by adding the dependency:
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.3</version>
</dependency>
Let's now walk through what the code is doing step-by-step:
Import Statements
We first import the necessary Jsoup classes:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
Jsoup provides the Document class to represent parsed HTML documents and the Elements class to represent lists of selected elements.
We also import classes for handling encoding, writing files and exceptions:
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
import java.net.URLEncoder;
Constructing the Yelp URL
We define the initial Yelp URL to scrape, searching for Chinese restaurants in San Francisco:
String url = "<https://www.yelp.com/search?find_desc=chinese&find_loc=San+Francisco%2C+CA>";
The find_desc and find_loc parameters allow narrowing down listings by description and location.
Encoding the URL
Certain characters in URLs can cause issues when making requests. We URL-encode the Yelp URL:
String encodedUrl = URLEncoder.encode(url, "UTF-8");
This escapes special characters into a valid format.
Constructing the API URL
We then construct the full API URL, inserting the encoded Yelp URL:
String api_url = "<http://api.proxiesapi.com/?premium=true&auth_key=YOUR_AUTH_KEY&url=>" + encodedUrl;
This routes requests through the proxy service. Be sure to insert your own auth_key.
Setting User-Agent Header
We define a user-agent header to mimic a real Chrome browser request:
String userAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36";
Making the GET Request
We make the HTTP GET request to the API URL constructed earlier:
Document doc = Jsoup.connect(api_url)
.header("User-Agent", userAgent)
.header("Accept-Language", "en-US,en;q=0.5")
.header("Accept-Encoding", "gzip, deflate, br")
.header("Referer", "<https://www.google.com/>")
.get();
Additional headers further mimic a real browser. The returned Document contains the full HTML of the rendered Yelp results page.
Writing HTML Response
We write the HTML content to a file for later parsing:
try (BufferedWriter writer = new BufferedWriter(new FileWriter("yelp_html.html"))) {
writer.write(doc.outerHtml());
}
Checking Request Success
It's good practice to verify the request was successful before trying to parse:
if (doc != null) {
// Parse HTML
} else {
System.out.println("Failed to retrieve data.");
}
Scraping the Data
Now that we have retrieved the Yelp search result page, we can programmatically extract information on each business listing.
Selector Basics
The key concept here is selectors. Jsoup selectors allow targeting elements in the HTML document based on CSS or jQuery-style queries.
Some examples:
doc.select("div"); // All <div> elements
doc.select("#biz-listing-id"); // Element with id="biz-listing-id"
doc.select(".business-name"); // Elements with class="business-name"
listing.select("span"); // All <span> inside some listing element
Selectors are analogous to finding needles in the HTML haystack, zeroing in on the data you want.
Scraping Listings
Inspecting the page
When we inspect the page we can see that the div has classes called arrange-unit__09f24__rqHTg arrange-unit-fill__09f24__CUubG css-1qn0b6x
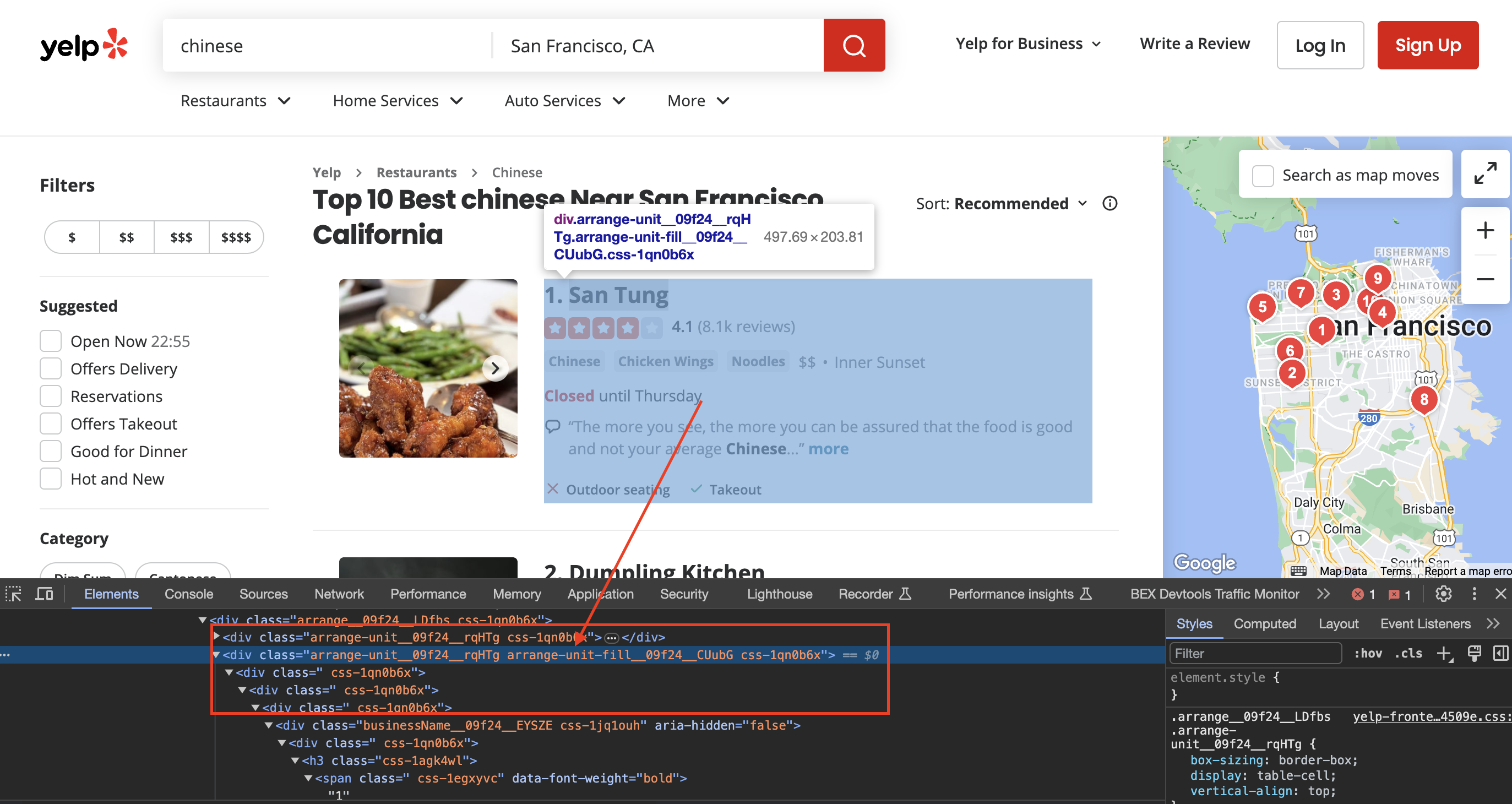
Let's walk through how the code isolates each listing:
Elements listings = doc.select("div.arrange-unit__09f24__rqHTg.arrange-unit-fill__09f24__CUubG.css-1qn0b6x");
This targets We loop through each listing Not all listings contain the same data. To handle missing values, we first check if elements exist before extracting: The .selectFirst() method returns only the first match instead of all matches. This targets the link containing the business name. We print N/A if no element matched. The same pattern is used when extracting rating, pricing, etc. Gracefully handling missing data prevents errors. For reviews and location, the approach is slightly different: Here we select all elements, then handle cases of 1 match or 2+ matches differently. This caters to variability in the data. Finally, we print out all the extracted information nicely formatted: The full code handles a number of edge cases and variability, enabling robust scraping even as listings change slightly over time. The full code seen earlier is provided again below in case you want to use it in your own projects: This covers the basics of scraping Yelp listings using Jsoup in Java. With the foundations you now have, you can expand on this to extract additional data points or scrape other pages. Potential next steps are storing the scraped data in databases or CSV files instead of just printing, then performing further analysis.
Get HTML from any page with a simple API call. We handle proxy rotation, browser identities, automatic retries, CAPTCHAs, JavaScript rendering, etc automatically for you
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com" <!doctype html> Enter your email below to claim your free API key:for (Element listing : listings) {
// Extract data from each listing
}
Handling Missing Data
Element businessNameElem = listing.selectFirst("a.css-19v1rkv");
if (businessNameElem != null) {
String businessName = businessNameElem.text();
} else {
String businessName = "N/A"; // Handle missing
}
Extracting Spans
Elements spanElements = listing.select("span.css-chan6m");
if (spanElements.size() >= 2) {
// Get first span for reviews
// Get second span for location
} else if (size == 1) {
// Check if span contains number or text
} else {
// Set to N/A
}
Printing Results
System.out.println("Name: " + name);
System.out.println("Reviews: " + reviews);
System.out.println("Location: " + location);
// etc
Key Takeaways
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
import java.net.URLEncoder;
public class YelpScraper {
public static void main(String[] args) {
// URL of the Yelp search page
String url = "https://www.yelp.com/search?find_desc=chinese&find_loc=San+Francisco%2C+CA";
try {
// URL-encode the URL
String encodedUrl = URLEncoder.encode(url, "UTF-8");
// API URL with the encoded Yelp URL
String api_url = "http://api.proxiesapi.com/?premium=true&auth_key=YOUR_AUTH_KEY&url=" + encodedUrl;
// Define user-agent header to simulate a browser request
String userAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36";
// Send an HTTP GET request to the URL with headers
Document doc = Jsoup.connect(api_url)
.header("User-Agent", userAgent)
.header("Accept-Language", "en-US,en;q=0.5")
.header("Accept-Encoding", "gzip, deflate, br")
.header("Referer", "https://www.google.com/")
.get();
// Write the HTML response to a file
try (BufferedWriter writer = new BufferedWriter(new FileWriter("yelp_html.html"))) {
writer.write(doc.outerHtml());
}
// Check if the request was successful (status code 200)
if (doc != null) {
// Find all the listings
Elements listings = doc.select("div.arrange-unit__09f24__rqHTg.arrange-unit-fill__09f24__CUubG.css-1qn0b6x");
System.out.println("Number of listings: " + listings.size());
// Loop through each listing and extract information
for (Element listing : listings) {
// Assuming you've already extracted the information as shown in your code
// Check if business name exists
Element businessNameElem = listing.selectFirst("a.css-19v1rkv");
String businessName = (businessNameElem != null) ? businessNameElem.text() : "N/A";
// If business name is not "N/A," then print the information
if (!businessName.equals("N/A")) {
// Check if rating exists
Element ratingElem = listing.selectFirst("span.css-gutk1c");
String rating = (ratingElem != null) ? ratingElem.text() : "N/A";
// Check if price range exists
Element priceRangeElem = listing.selectFirst("span.priceRange__09f24__mmOuH");
String priceRange = (priceRangeElem != null) ? priceRangeElem.text() : "N/A";
// Find all <span> elements inside the listing
Elements spanElements = listing.select("span.css-chan6m");
// Initialize num_reviews and location as "N/A"
String numReviews = "N/A";
String location = "N/A";
// Check if there are at least two <span> elements
if (spanElements.size() >= 2) {
// The first <span> element is for Number of Reviews
numReviews = spanElements.get(0).text().trim();
// The second <span> element is for Location
location = spanElements.get(1).text().trim();
} else if (spanElements.size() == 1) {
// If there's only one <span> element, check if it's for Number of Reviews or Location
String text = spanElements.get(0).text().trim();
if (text.matches("\\d+")) {
numReviews = text;
} else {
location = text;
}
}
// Print the extracted information
System.out.println("Business Name: " + businessName);
System.out.println("Rating: " + rating);
System.out.println("Number of Reviews: " + numReviews);
System.out.println("Price Range: " + priceRange);
System.out.println("Location: " + location);
System.out.println("==============================");
}
}
} else {
System.out.println("Failed to retrieve data.");
}
} catch (IOException e) {
e.printStackTrace();
}
}
}Browse by tags:
Browse by language:
The easiest way to do Web Scraping
Try ProxiesAPI for free
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
...Don't leave just yet!