In this article, we will be scraping Reddit to extract information from posts using Perl. We will get the HTML content of a Reddit page, parse it to find post blocks, and extract the permalink, title, author, comments count and other fields from each block.
here is the page we are talking about
Modules Used
Here are the modules we use:
LWP::UserAgent - Makes HTTP requests and handles cookies, authorization, proxies, etc. Needed to download the Reddit page.
HTML::TreeBuilder - Parses HTML and allows traversal/extraction of data. We use it to parse the Reddit HTML and find posts.
Strict - Requires variables be declared with
Warnings - Catches errors, undefined variables, etc.
No special installation needed for these core Perl modules.
Code Walkthrough
Define Reddit URL
my $reddit_url = "<https://www.reddit.com>";
We define the Reddit URL we want to scrape. I use the front page but we could use any subreddit or thread URL.
Create a User Agent
my $user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36";
We make a browser User Agent string to identify as a real browser. Sites may block automated bot requests.
Make a UserAgent Object
my $ua = LWP::UserAgent->new;
$ua->agent($user_agent);
We create a
Send Request with UA Header
my $response = $ua->get($reddit_url);
We make a GET request to the Reddit URL using the
Check if Successful
if ($response->is_success) {
# save HTML
} else {
print "Request failed";
}
We check if the response status code is 200 OK for success. If so we continue, otherwise we print an error.
Save HTML to File
open my $file, '>:encoding(utf-8)', $filename or die "Could not open $filename: $!";
print $file $html_content;
close $file;
We save the HTML content to a file named
Parse HTML
my $tree = HTML::TreeBuilder->new;
$tree->parse_content($response->content);
We create a new
Find Post Blocks
Inspecting the elements
Upon inspecting the HTML in Chrome, you will see that each of the posts have a particular element shreddit-post and class descriptors specific to them…
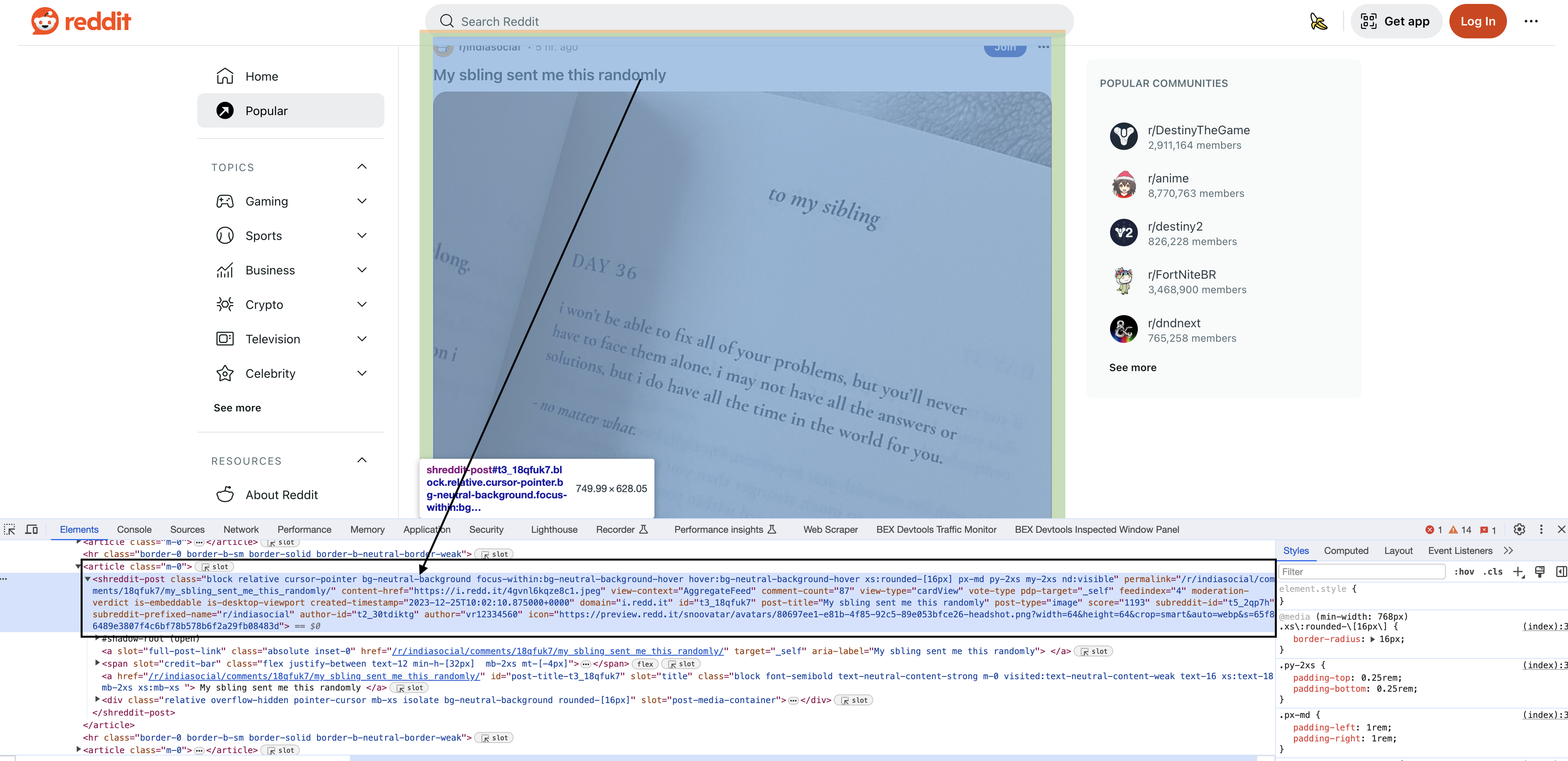
my @blocks = $tree->look_down(
'_tag' => 'shreddit-post',
'class' => qr/block relative cursor-pointer bg-neutral-background focus-within:bg-neutral-background-hover hover:bg-neutral-background-hover xs:rounded-\\\\\\[16px\\\\\\] p-md my-2xs nd:visible/
);
This is where we locate the posts within the large HTML document. We use the
This is the most complex part for beginners. We are extracting the posts by matching the literal HTML attributes and class name.
The
Extract Post Data
foreach my $block (@blocks) {
my $permalink = $block->attr('permalink');
my $title = $block->look_down('_tag' => 'div', 'slot' => 'title')->as_text;
print "Permalink: $permalink\\n";
print "Title: $title\\n";
}
We loop through each block and use
We get the permalink from the block's attribute. We look deeper into the block to find the title element and get its text.
We print out the extracted data. Do this for all fields needed.
Clean Up
$tree->delete;
Delete the tree when done to free memory.
Full Code
use LWP::UserAgent;
use HTML::TreeBuilder;
use strict;
use warnings;
# Define the Reddit URL you want to download
my $reddit_url = "https://www.reddit.com";
# Define a User-Agent header
my $user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"; # Replace with your User-Agent string
# Create a UserAgent object
my $ua = LWP::UserAgent->new;
$ua->agent($user_agent);
# Send a GET request to the URL with the User-Agent header
my $response = $ua->get($reddit_url);
# Check if the request was successful (status code 200)
if ($response->is_success) {
# Get the HTML content of the page
my $html_content = $response->content;
# Specify the filename to save the HTML content
my $filename = "reddit_page.html";
# Save the HTML content to a file
open my $file, '>:encoding(utf-8)', $filename or die "Could not open $filename: $!";
print $file $html_content;
close $file;
print "Reddit page saved to $filename\n";
} else {
print "Failed to download Reddit page (status code " . $response->status_line . ")\n";
}
# Parse the entire HTML content
my $tree = HTML::TreeBuilder->new;
$tree->parse_content($response->content);
# Find all blocks with the specified tag and class
my @blocks = $tree->look_down(
'_tag' => 'shreddit-post',
'class' => qr/block relative cursor-pointer bg-neutral-background focus-within:bg-neutral-background-hover hover:bg-neutral-background-hover xs:rounded-\[16px\] p-md my-2xs nd:visible/
);
# Iterate through the blocks and extract information from each one
foreach my $block (@blocks) {
my $permalink = $block->attr('permalink');
my $content_href = $block->attr('content-href');
my $comment_count = $block->attr('comment-count');
my $post_title = $block->look_down('_tag' => 'div', 'slot' => 'title')->as_text;
my $author = $block->attr('author');
my $score = $block->attr('score');
# Print the extracted information for each block
print "Permalink: $permalink\n";
print "Content Href: $content_href\n";
print "Comment Count: $comment_count\n";
print "Post Title: $post_title\n";
print "Author: $author\n";
print "Score: $score\n\n";
}
# Clean up
$tree->delete;