Web scraping refers to programmatically extracting data from websites. Here we'll use C# and the handy HtmlAgilityPack library to scrape real estate listing data from Realtor.com.
We'll walk through a full working script, explain how each part functions, and pay special attention to the key data extraction logic. We assume some programming experience but aim to provide ample detail for beginners.
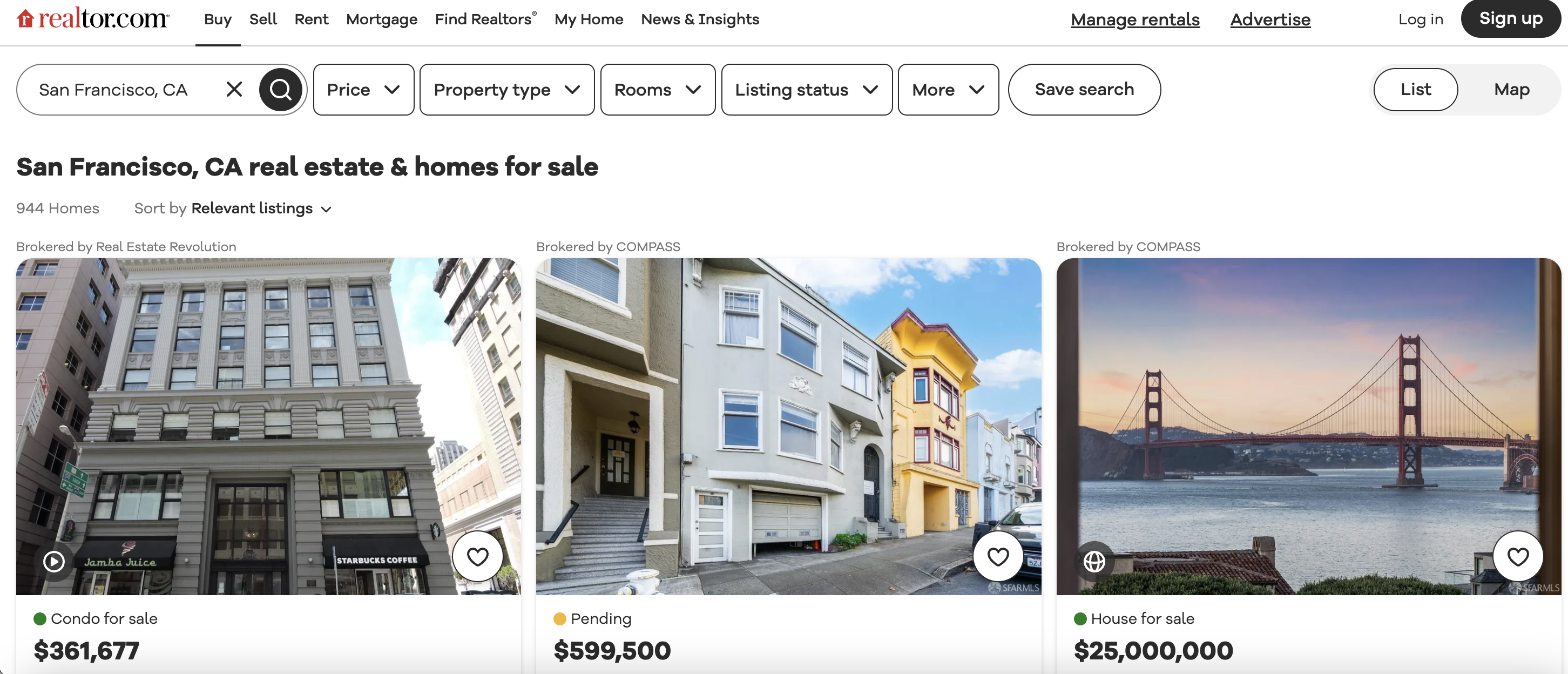
This is the listings page we are talking about…
Getting Set Up
Since we are using C#, you will need:
To install this last dependency, search "HtmlAgilityPack" in the NuGet package manager interface in your IDE of choice. Once added to your project, you can access all functionality via the
Now let's dive into the code!
Walkthrough
First we import namespaces:
using System;
using System.Net.Http;
using HtmlAgilityPack;
The key one here is
Next we define our target URL and user agent string:
string url = "<https://www.realtor.com/realestateandhomes-search/San-Francisco_CA>";
string userAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36";
I opted to scrape listings in San Francisco, but this could be any location search on Realtor.com.
The user agent mimics a Chrome browser. Sites like Realtor will block suspicious requests lacking user agent info.
We next construct an
HttpClient httpClient = new HttpClient();
httpClient.DefaultRequestHeaders.Add("User-Agent", userAgent);
Now we can make the GET request to fetch the page HTML:
HttpResponseMessage response = await httpClient.GetAsync(url);
It's smart to check that the request succeeded before trying to parse:
if (response.IsSuccessStatusCode)
{
// scraping logic here
}
else {
Console.WriteLine("Failed to retrieve the page. Status code: " + (int)response.StatusCode);
}
Okay, we have fetched the page HTML. Time to extract data!
We load up an
string htmlContent = await response.Content.ReadAsStringAsync();
HtmlDocument htmlDocument = new HtmlDocument();
htmlDocument.LoadHtml(htmlContent);
Now the
Inspecting the element
When we inspect element in Chrome we can see that each of the listing blocks is wrapped in a div with a class value as shown below…
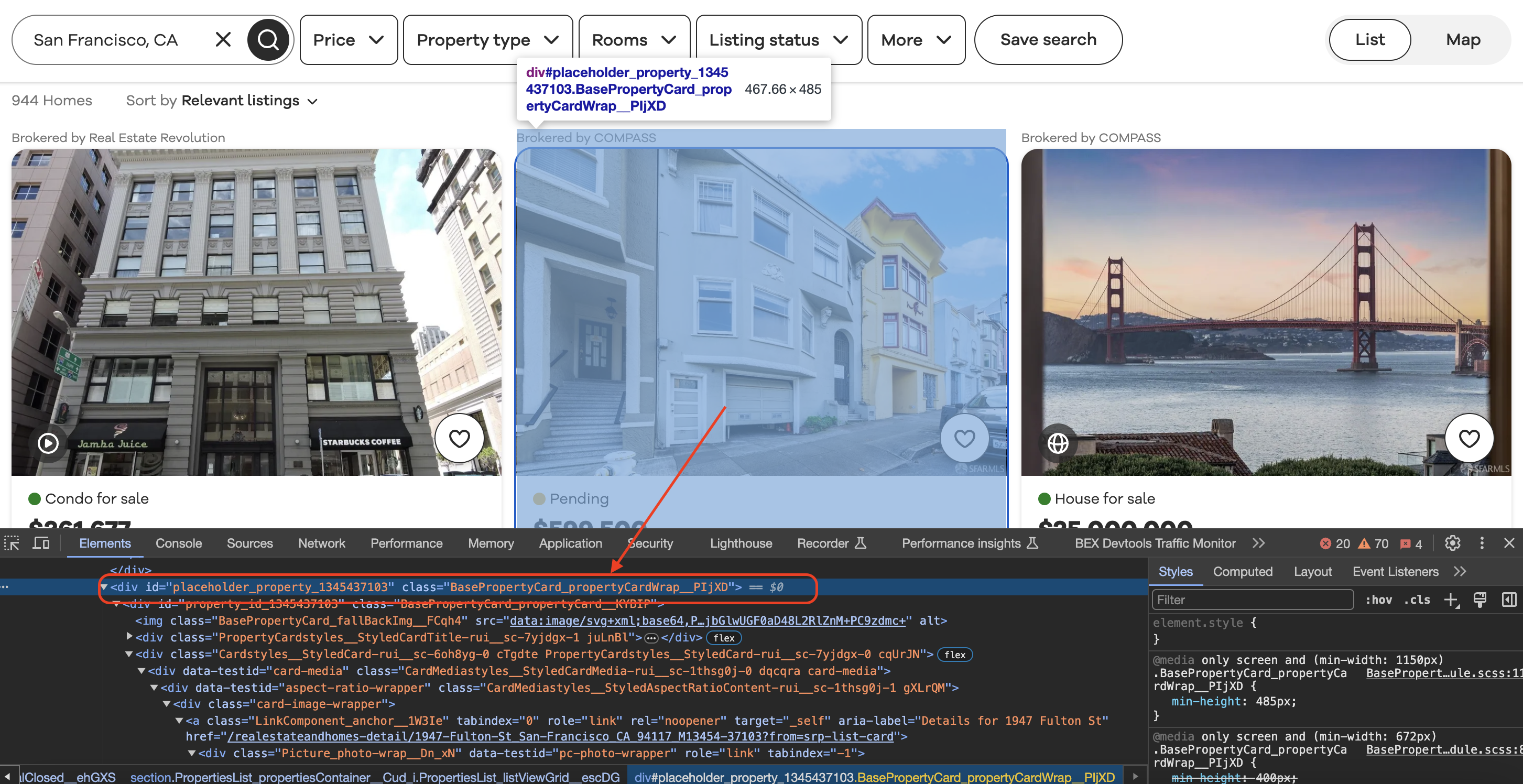
We can use XPath queries to pinpoint specific elements and extract inner text values. This is usually the trickiest part for beginners.
Let's break it down step-by-step:
var listingBlocks = htmlDocument.DocumentNode.SelectNodes("//div[contains(@class, 'BasePropertyCard_propertyCardWrap__J0xUj')]");
This grabs all the high level
We then iterate through each listing:
foreach (var listingBlock in listingBlocks)
{
// Extract data for this listing
}
Inside here we can apply more XPath queries against
For example the broker name and company:
var brokerInfo = listingBlock.SelectSingleNode(".//div[contains(@class, 'BrokerTitle_brokerTitle__ZkbBW')]");
string brokerName = brokerInfo.SelectSingleNode(".//span[contains(@class, 'BrokerTitle_titleText__20u1P')]").InnerText.Trim();
We grab the high level broker
Some other examples:
Price:
string price = listingBlock.SelectSingleNode(".//div[contains(@class, 'card-price')]").InnerText.Trim();
Address:
string address = listingBlock.SelectSingleNode(".//div[contains(@class, 'card-address')]").InnerText.Trim();
Beds and baths:
string beds = listingBlock.SelectSingleNode(".//li[@data-testid='property-meta-beds']").InnerText.Trim();
string baths = listingBlock.SelectSingleNode(".//li[@data-testid='property-meta-baths']").InnerText.Trim();
Here we leveraged a
At the end, we print the extracted data:
Console.WriteLine("Broker: " + brokerName);
// etc
And that's the core of it! The full code:
using System;
using System.Net.Http;
using HtmlAgilityPack;
class Program
{
static async System.Threading.Tasks.Task Main(string[] args)
{
// Define the URL of the Realtor.com search page
string url = "https://www.realtor.com/realestateandhomes-search/San-Francisco_CA";
// Define a User-Agent header
string userAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36";
// Create an HttpClient with the User-Agent header
HttpClient httpClient = new HttpClient();
httpClient.DefaultRequestHeaders.Add("User-Agent", userAgent);
// Send a GET request to the URL
HttpResponseMessage response = await httpClient.GetAsync(url);
// Check if the request was successful (status code 200)
if (response.IsSuccessStatusCode)
{
// Parse the HTML content of the page using HtmlAgilityPack
string htmlContent = await response.Content.ReadAsStringAsync();
HtmlDocument htmlDocument = new HtmlDocument();
htmlDocument.LoadHtml(htmlContent);
// Find all the listing blocks using the provided class name
var listingBlocks = htmlDocument.DocumentNode.SelectNodes("//div[contains(@class, 'BasePropertyCard_propertyCardWrap__J0xUj')]");
// Loop through each listing block and extract information
foreach (var listingBlock in listingBlocks)
{
// Extract the broker information
var brokerInfo = listingBlock.SelectSingleNode(".//div[contains(@class, 'BrokerTitle_brokerTitle__ZkbBW')]");
string brokerName = brokerInfo.SelectSingleNode(".//span[contains(@class, 'BrokerTitle_titleText__20u1P')]").InnerText.Trim();
// Extract the status (e.g., For Sale)
string status = listingBlock.SelectSingleNode(".//div[contains(@class, 'message')]").InnerText.Trim();
// Extract the price
string price = listingBlock.SelectSingleNode(".//div[contains(@class, 'card-price')]").InnerText.Trim();
// Extract other details like beds, baths, sqft, and lot size
string beds = listingBlock.SelectSingleNode(".//li[@data-testid='property-meta-beds']").InnerText.Trim();
string baths = listingBlock.SelectSingleNode(".//li[@data-testid='property-meta-baths']").InnerText.Trim();
string sqft = listingBlock.SelectSingleNode(".//li[@data-testid='property-meta-sqft']").InnerText.Trim();
string lotSize = listingBlock.SelectSingleNode(".//li[@data-testid='property-meta-lot-size']").InnerText.Trim();
// Extract the address
string address = listingBlock.SelectSingleNode(".//div[contains(@class, 'card-address')]").InnerText.Trim();
// Print the extracted information
Console.WriteLine("Broker: " + brokerName);
Console.WriteLine("Status: " + status);
Console.WriteLine("Price: " + price);
Console.WriteLine("Beds: " + beds);
Console.WriteLine("Baths: " + baths);
Console.WriteLine("Sqft: " + sqft);
Console.WriteLine("Lot Size: " + lotSize);
Console.WriteLine("Address: " + address);
Console.WriteLine(new string('-', 50)); // Separating listings
}
}
else
{
Console.WriteLine("Failed to retrieve the page. Status code: " + (int)response.StatusCode);
}
}
}
There are many optimizations we could make, but hopefully this gives a good overview of how to harness the power of HtmlAgilityPack and XPath to scrape webpages in C#.