eBay is one of the largest online marketplaces with millions of active listings at any given time. In this tutorial, we'll walk through how to scrape and extract key data from eBay listings using Java and the JSoup library.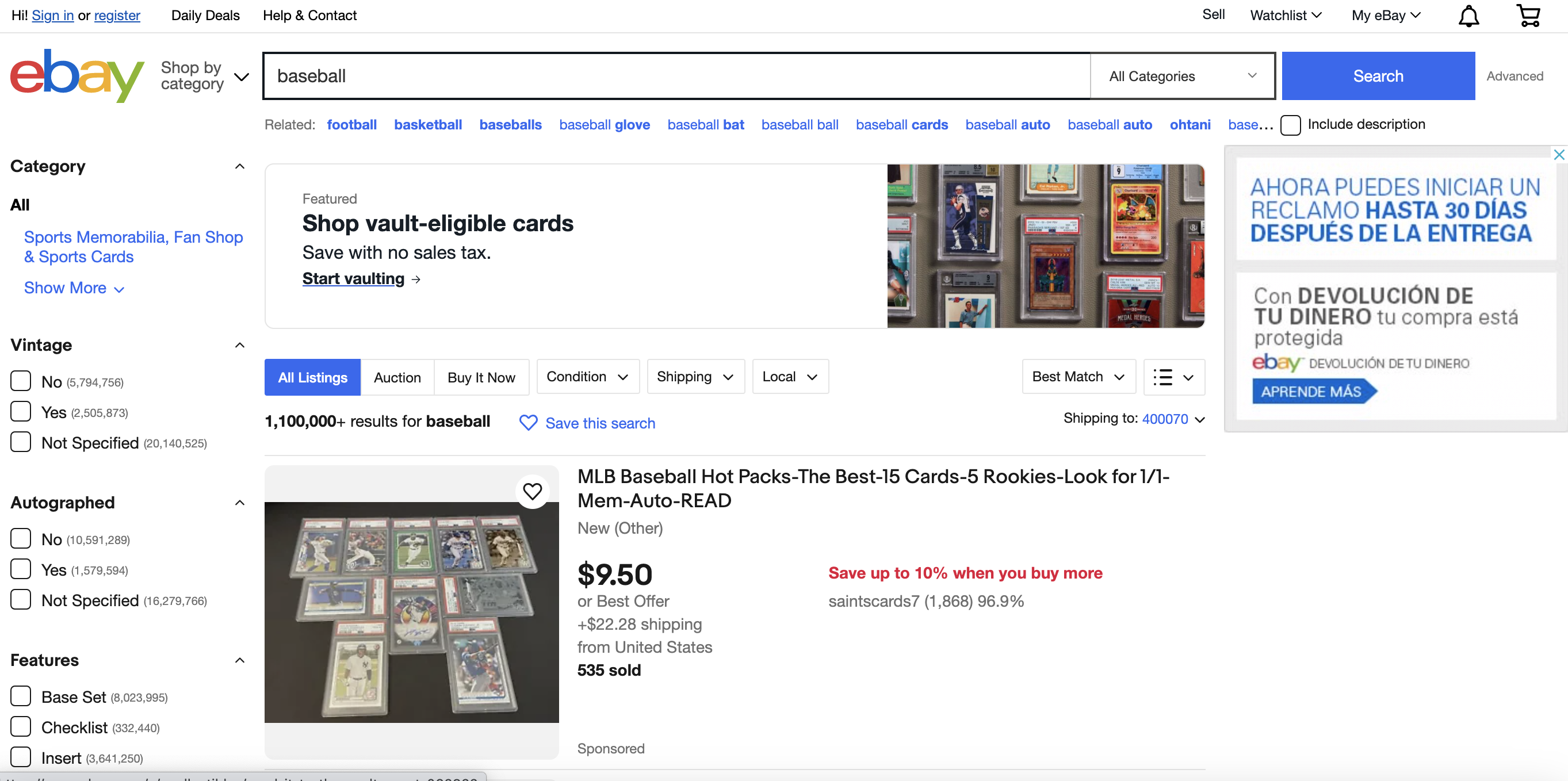
Setup
We'll need to add the JSoup dependency:
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.14.3</version>
</dependency>
And import it:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
We'll also define the starting eBay URL and a user agent string:
String url = "<https://www.ebay.com/sch/i.html?_nkw=baseball>";
String userAgent = "Mozilla/5.0 ...";
Replace the user agent with your browser's user agent string.
Fetch the Listings Page
We can use the JSoup Connection class to send the request:
Document doc = Jsoup.connect(url)
.userAgent(userAgent)
.get();
The user agent is set and the page HTML is loaded into a Document.
Extract Listing Data
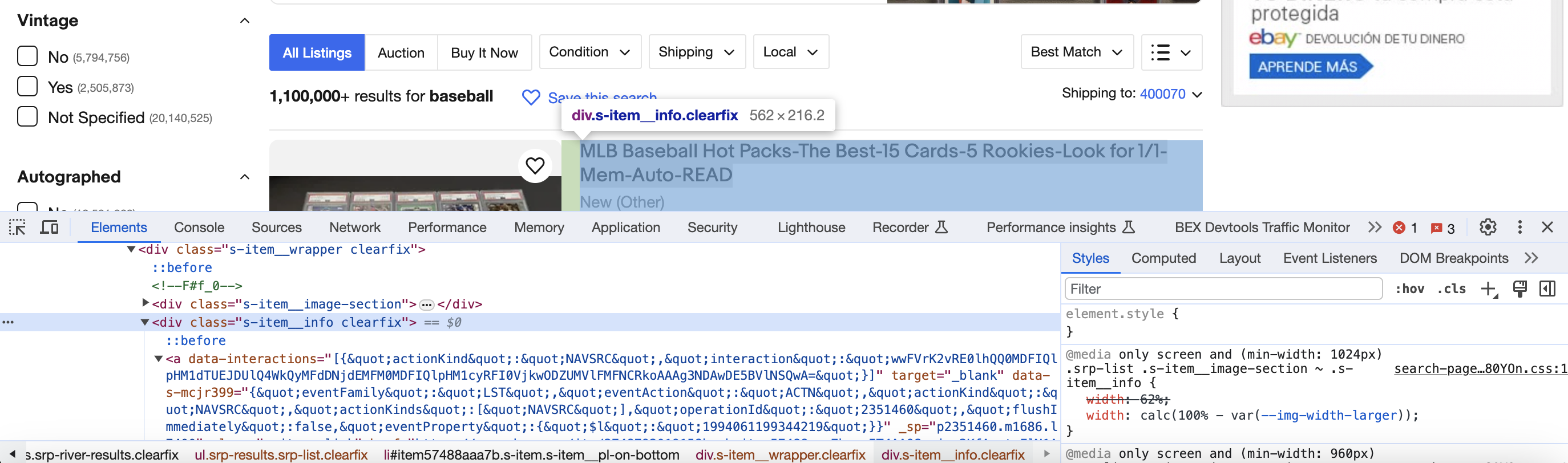
We can now use CSS selectors to extract data:
Elements listings = doc.select("div.s-item__info");
for (Element listing : listings) {
String title = listing.select("div.s-item__title").text();
String url = listing.select("a.s-item__link").attr("href");
String price = listing.select("span.s-item__price").text();
// Extract other fields like seller, shipping, etc.
}
We find the listings and extract text/attributes from elements.
Print Results
We can print out the extracted data:
System.out.println("Title: " + title);
System.out.println("URL: " + url);
System.out.println("Price: " + price);
System.out.println("=".repeat(50)); // Separator between listings
This will output each listing's info.
Full Code
Here is the full code to scrape eBay listings:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
public class eBayScraper {
public static void main(String[] args) throws IOException {
String url = "<https://www.ebay.com/sch/i.html?_nkw=baseball>";
String userAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36";
Document doc = Jsoup.connect(url)
.userAgent(userAgent)
.get();
Elements listings = doc.select("div.s-item__info");
for (Element listing : listings) {
String title = listing.select("div.s-item__title").text();
String url = listing.select("a.s-item__link").attr("href");
String price = listing.select("span.s-item__price").text();
String details = listing.select("div.s-item__subtitle").text();
String sellerInfo = listing.select("span.s-item__seller-info-text").text();
String shippingCost = listing.select("span.s-item__shipping").text();
String location = listing.select("span.s-item__location").text();
String sold = listing.select("span.s-item__quantity-sold").text();
System.out.println("Title: " + title);
System.out.println("URL: " + url);
System.out.println("Price: " + price);
System.out.println("Details: " + details);
System.out.println("Seller: " + sellerInfo);
System.out.println("Shipping: " + shippingCost);
System.out.println("Location: " + location);
System.out.println("Sold: " + sold);
System.out.println("=".repeat(50));
}
}
}