This article explains how to scrape Craigslist apartment listings using Kotlin and the Ktor client library. We'll go through each part of the code.
First add Ktor to build.gradle.kts:
implementation("io.ktor:ktor-client-core:1.5.2")
implementation("io.ktor:ktor-client-cio:1.5.2")
Import the Ktor client:
import io.ktor.client.*
Ktor provides a HttpClient for HTTP requests.
Set the URL to scrape:
val url = "<https://sfbay.craigslist.org/search/apa>"
Make the HTTP request and get the response text:
val client = HttpClient()
val response = client.get<String>(url)
val html = response.body()
Parse the HTML using kotlinx.html:
val doc = HtmlParser.parse(html)
If you check the source code of Craigslist listings you can see that the listings area code looks something like this…
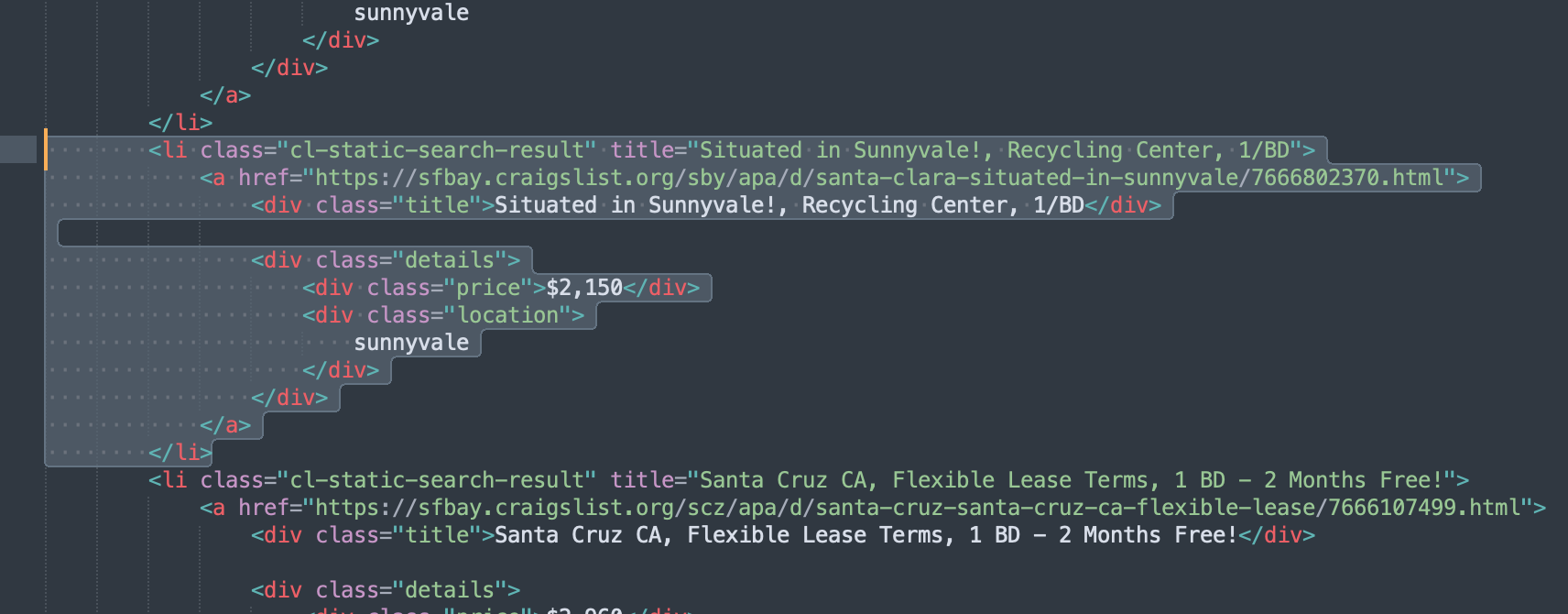
You can see the code block that generates the listing…
<li class="cl-static-search-result" title="Situated in Sunnyvale!, Recycling Center, 1/BD">
<a href="https://sfbay.craigslist.org/sby/apa/d/santa-clara-situated-in-sunnyvale/7666802370.html">
<div class="title">Situated in Sunnyvale!, Recycling Center, 1/BD</div>
<div class="details">
<div class="price">$2,150</div>
<div class="location">
sunnyvale
</div>
</div>
</a>
</li>its encapsulated in the cl-static-search-result class. We also need to get the title class div and the price and location class divs to get all the data
Find all listing nodes with select:
val listings = doc.select("li.cl-static-search-result")
Loop through listings and extract info:
for (listing in listings) {
val title = listing.select(".title").text()
val price = listing.select(".price").text()
val location = listing.select(".location").text()
val link = listing.select("a").attr("href")
println("$title $price $location $link")
}
The full Kotlin code:
import io.ktor.client.*
import kotlinx.html.*
val url = "<https://sfbay.craigslist.org/search/apa>"
val client = HttpClient()
val response = client.get<String>(url)
val html = response.body()
val doc = HtmlParser.parse(html)
val listings = doc.select("li.cl-static-search-result")
for (listing in listings) {
val title = listing.select(".title").text()
val price = listing.select(".price").text()
val location = listing.select(".location").text()
val link = listing.select("a").attr("href")
println("$title $price $location $link")
}
This walks through scraping Craigslist listings in Kotlin.
This is great as a learning exercise but it is easy to see that even the proxy server itself is prone to get blocked as it uses a single IP. In this scenario where you may want a proxy that handles thousands of fetches every day using a professional rotating proxy service to rotate IPs is almost a must.
Otherwise, you tend to get IP blocked a lot by automatic location, usage, and bot detection algorithms.
Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly.
Hundreds of our customers have successfully solved the headache of IP blocks with a simple API.
The whole thing can be accessed by a simple API like below in any programming language.
In fact, you don't even have to take the pain of loading Puppeteer as we render Javascript behind the scenes and you can just get the data and parse it any language like Node, Puppeteer or PHP or using any framework like Scrapy or Nutch. In all these cases you can just call the URL with render support like so:
curl "<http://api.proxiesapi.com/?key=API_KEY&render=true&url=https://example.com>"
We have a running offer of 1000 API calls completely free. Register and get your free API Key.