This article explains in detail how to write a program in Go that downloads a Reddit page and extracts information about posts. It's aimed at beginners who want a step-by-step guide to web scraping Reddit with Go.
here is the page we are talking about
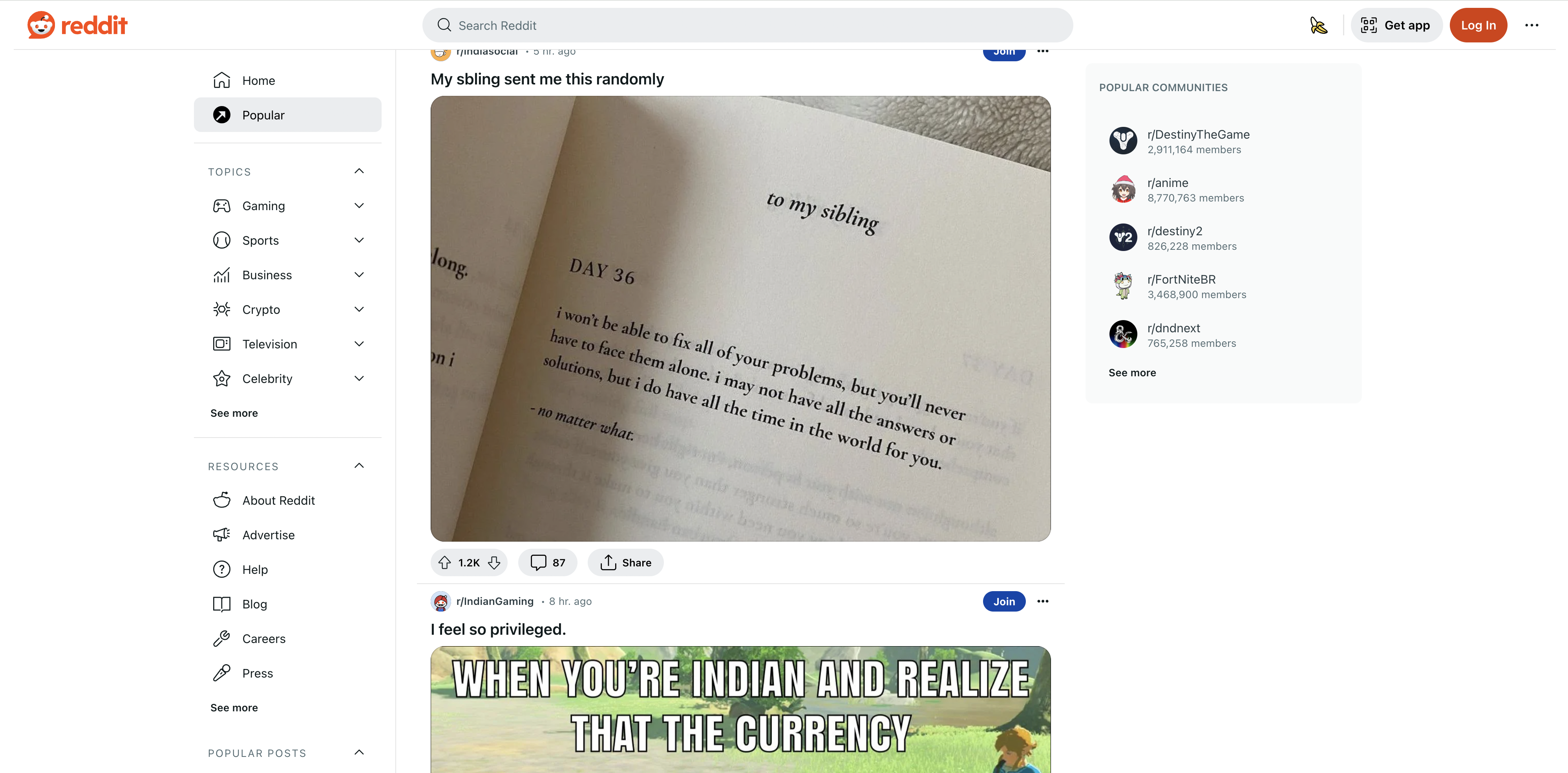
Prerequisites
To follow along, you'll need:
go get github.com/PuerkitoBio/goquery
Overview
Here's a quick overview of what the program does:
- Defines the Reddit URL to download and a User-Agent string
- Makes a GET request to the URL using the User-Agent
- Checks if the request succeeded (200 status code)
- Saves the HTML content from the response to a file
- Parses the HTML content using
goquery - Finds div elements with certain classes using a selector
- Loops through the elements, extracting various attributes
- Prints the extracted data - permalinks, comments count, etc.
Now let's walk through exactly how it works.
Importing Packages
We import several packages that provide the functionality we need:
import (
"fmt"
"io/ioutil"
"net/http"
"os"
"strings"
"github.com/PuerkitoBio/goquery"
)
Defining Variables
Next we set some key variables:
// URL of Reddit page
redditURL := "<https://www.reddit.com>"
// User agent header
userAgent := "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"
The user agent mimics a desktop Chrome browser. Some websites block scraping bots, so this allows our request to look like a normal browser visit.
Making the GET Request
We make a GET request to the Reddit URL using the defined user agent:
// HTTP client
client := &http.Client{}
req, err := http.NewRequest("GET", redditURL, nil)
if err != nil {
// ... handle error
}
req.Header.Set("User-Agent", userAgent)
resp, err := client.Do(req)
if err != nil {
// ... handle error
}
We create a new HTTP client, make a GET request to the URL, set the user agent header, send the request and get the response.
Checking Status
It's important to check if the request succeeded before trying to read the response:
if resp.StatusCode == 200 {
// Request succeeded!
// Proceed to parse response...
} else {
// Handle error
fmt.Printf("Failed, status code %d", resp.StatusCode)
}
A status code of 200 means success. Any other code means an error occurred.
Saving HTML
We can save the HTML content to a file for inspection:
bodyBytes, _ := ioutil.ReadAll(resp.Body)
htmlContent := string(bodyBytes)
filename := "reddit_page.html"
ioutil.WriteFile(filename, []byte(htmlContent), 0644)
fmt.Printf("Saved to %s", filename)
This reads the response body into a byte slice, converts it to a string, and writes it out.
Parsing HTML with goquery
Now we have the HTML content, we can parse it and extract data using the
First we load it into a goquery document:
reader := strings.NewReader(htmlContent)
doc, err := goquery.NewDocumentFromReader(reader)
This parses the HTML string into a queryable document.
Selecting Elements
Inspecting the elements
Upon inspecting the HTML in Chrome, you will see that each of the posts have a particular element shreddit-post and class descriptors specific to them…
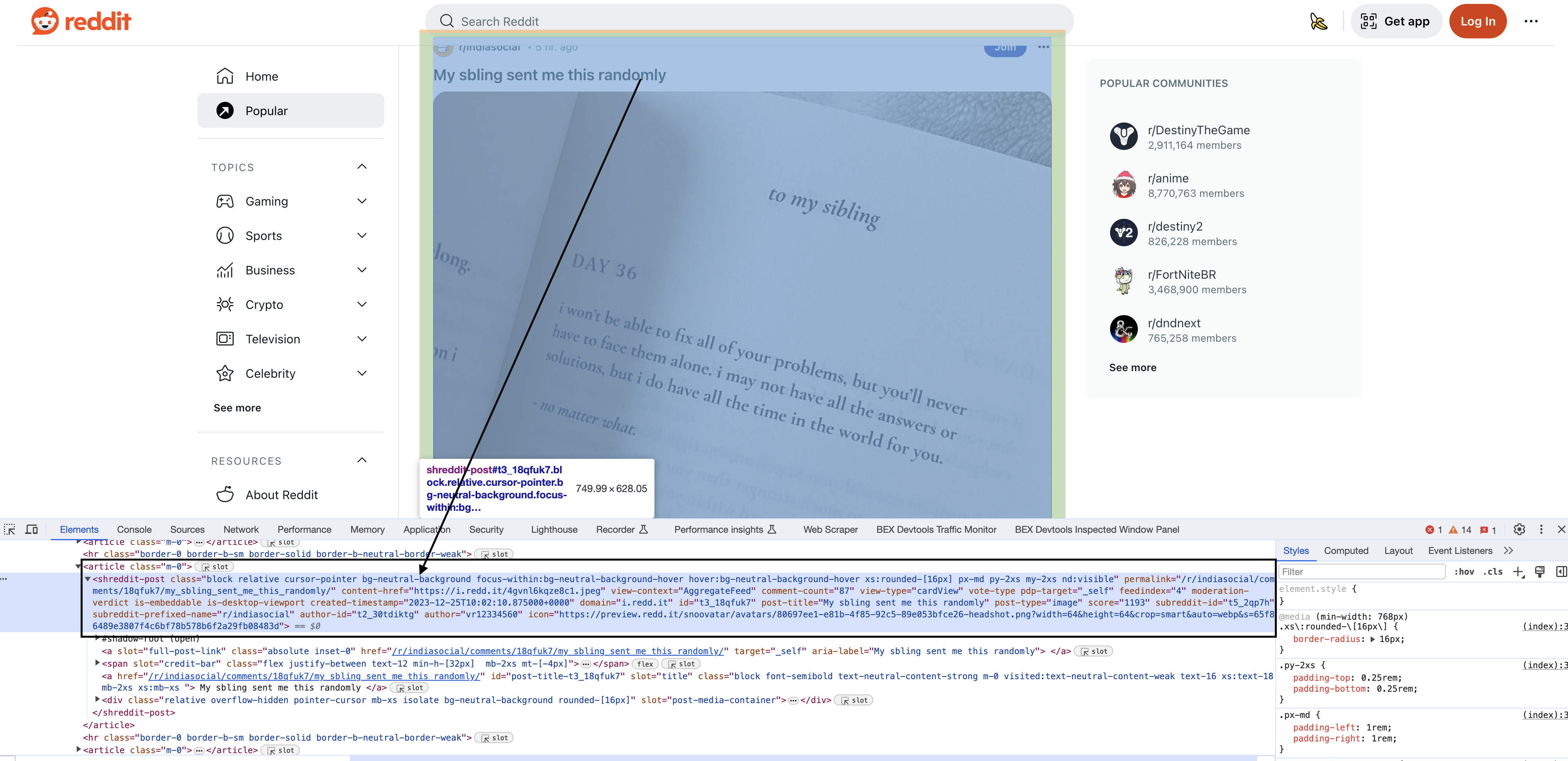
goquery allows us to use CSS selectors to find elements, just like jQuery.
Let's go through this complex selector step-by-step:
doc.Find("div.block.relative.cursor-pointer.bg-neutral-background.focus-within:bg-neutral-background-hover.hover:bg-neutral-background-hover.xs:rounded-[16px].p-md.my-2xs.nd:visible")
Breaking it down:
This selects "card" div elements having the various classes and attributes specified.
Why go through each part?. Selectors can get complex, so understanding what each piece matches is important.
Looping Through Elements
We can now loop through the matching elements and extract data from each:
doc.Find("div.block...").Each(func(i int, s *goquery.Selection) {
// Extract data from current element as s
})
The .Each method calls the function for each element found, passing in the loop index and the current selection.
Let's look at what we extract from each card element:
Extracting the permalink
We get the permalink URL using the
permalink, _ := s.Attr("permalink")
Getting the content URL
The content URL is stored in
contentHref, _ := s.Attr("content-href")
Fetching comment count
The number of comments is in
commentCount, _ := s.Attr("comment-count")
Scraping the post title
We can query within the current selection to get the title element, then extract its text:
postTitle := s.Find("div[slot=title]").Text()
This selects the The author name and score attributes extract similarly: Finally, we print out each extracted attribute, for example: And that covers the key parts of how this Reddit scraping script works! Let's recap... Here is the complete code to scrape Reddit posts in Go covered in this article: By breaking down each step, I hope it's clearer how we:
Get HTML from any page with a simple API call. We handle proxy rotation, browser identities, automatic retries, CAPTCHAs, JavaScript rendering, etc automatically for you
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com" <!doctype html>Getting author and score
author, _ := s.Attr("author")
score, _ := s.Attr("score")
Printing the data
Permalink: <https://www.reddit.com/r/videos/comments/xxxxxxxx>
Content URL: <https://v.redd.it/yyyyyyyyy>
Comment Count: 5823
Post Title: My favorite cat video
Author: cool_dude94
Score: 15338
Full Code
package main
import (
"fmt"
"io/ioutil"
"net/http"
"os"
"strings"
"github.com/PuerkitoBio/goquery"
)
func main() {
// Define the Reddit URL you want to download
redditURL := "https://www.reddit.com"
// Define a User-Agent header
userAgent := "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"
// Create an HTTP client with the specified User-Agent
client := &http.Client{}
req, err := http.NewRequest("GET", redditURL, nil)
if err != nil {
fmt.Printf("Failed to create a request: %v\n", err)
return
}
req.Header.Set("User-Agent", userAgent)
// Send the GET request to the URL with the User-Agent header
resp, err := client.Do(req)
if err != nil {
fmt.Printf("Failed to send GET request: %v\n", err)
return
}
defer resp.Body.Close()
// Check if the request was successful (status code 200)
if resp.StatusCode == 200 {
// Read the HTML content of the page
bodyBytes, err := ioutil.ReadAll(resp.Body)
if err != nil {
fmt.Printf("Failed to read response body: %v\n", err)
return
}
htmlContent := string(bodyBytes)
// Specify the filename to save the HTML content
filename := "reddit_page.html"
// Save the HTML content to a file
err = ioutil.WriteFile(filename, []byte(htmlContent), 0644)
if err != nil {
fmt.Printf("Failed to save HTML content to a file: %v\n", err)
} else {
fmt.Printf("Reddit page saved to %s\n", filename)
}
// Parse the HTML content
reader := strings.NewReader(htmlContent)
doc, err := goquery.NewDocumentFromReader(reader)
if err != nil {
fmt.Printf("Failed to parse HTML content: %v\n", err)
return
}
// Find all blocks with the specified tag and class
doc.Find("div.block.relative.cursor-pointer.bg-neutral-background.focus-within:bg-neutral-background-hover.hover:bg-neutral-background-hover.xs:rounded-[16px].p-md.my-2xs.nd:visible").Each(func(i int, s *goquery.Selection) {
permalink, _ := s.Attr("permalink")
contentHref, _ := s.Attr("content-href")
commentCount, _ := s.Attr("comment-count")
postTitle := s.Find("div[slot=title]").Text()
author, _ := s.Attr("author")
score, _ := s.Attr("score")
// Print the extracted information for each block
fmt.Println("Permalink:", permalink)
fmt.Println("Content Href:", contentHref)
fmt.Println("Comment Count:", commentCount)
fmt.Println("Post Title:", postTitle)
fmt.Println("Author:", author)
fmt.Println("Score:", score)
fmt.Println()
})
} else {
fmt.Printf("Failed to download Reddit page (status code %d)\n", resp.StatusCode)
}
}
Browse by tags:
Browse by language:
The easiest way to do Web Scraping
Try ProxiesAPI for free
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
...
Don't leave just yet!
Enter your email below to claim your free API key: